- Describe the open source Delta Lake – Learn | Microsoft Docs
- Table batch reads and writes | Databricks on AWS
- Delta Lake Batch Operations – Create
- Delta Lake Batch Operations – Append
- Delta Lake Batch Operations – Upsert
- Merge ด้วย Python
You will notice that throughout this course, there is a lot of context switching between PySpark/Scala and SQL. This is because:
readandwriteoperations are performed on DataFrames using PySpark or Scala- table creates and queries are performed directly off Delta Lake tables using SQL
1. Delta Lake Batch Operations – Create
Creating Delta Lakes is as easy as changing the file type while performing a write. In this section, we’ll read from a CSV and write to Delta.
%fs ls /mnt/training/delta/sample_csv/
inputPath = "/mnt/training/sample.tsv" DataPath = "/mnt/training/delta/sample_csv/" #remove directory if it exists dbutils.fs.rm(DataPath, True)
- Read the data into a DataFrame. We supply the schema.
- Use overwrite mode so that there will not be an issue in rewriting the data in case you end up running the cell again.
- Partition on
Country(name) because there are only a few unique countries and because we will useCountryas a predicate in aWHEREclause.
Then write the data to Delta Lake.
pip install pyspark
from pyspark.sql.types import StructType, StructField, DoubleType, IntegerType, StringType
inputSchema = StructType([
StructField("ID", IntegerType(), True),
StructField("Name", StringType(), True),
StructField("Weight", IntegerType(), True)
])
rawDataDF = (spark.read
.option("header", "true")
.option("sep", "\t")
.schema(inputSchema)
.csv(inputPath)
)
# write to Delta Lake
rawDataDF.write.mode("overwrite").format("delta").partitionBy("Name").save(DataPath)
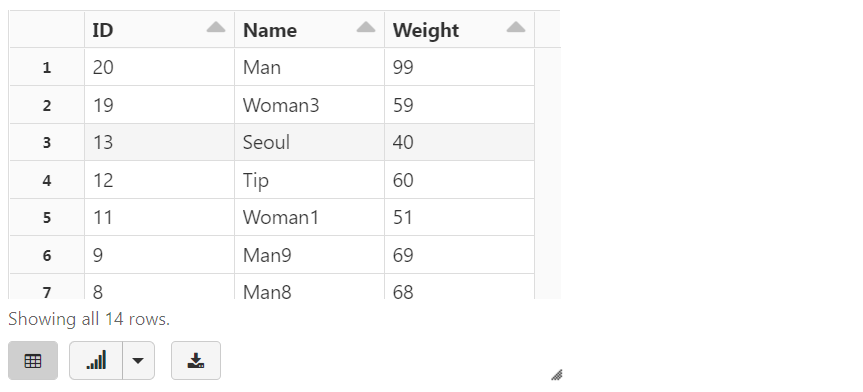
rawDataDF.printSchema()
display(rawDataDF)
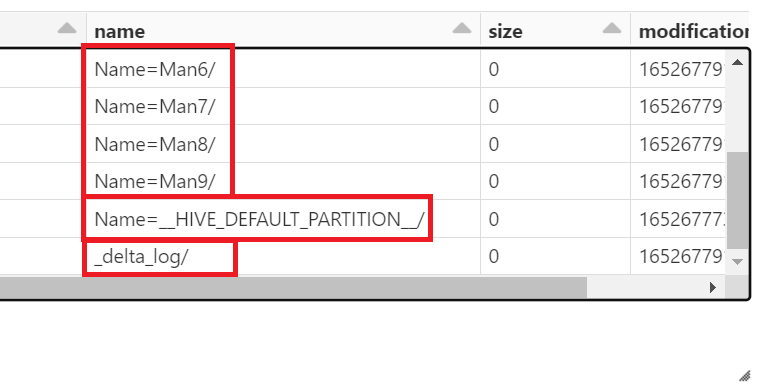
%fs ls /mnt/training/delta/sample_csv/
While we show creating a table in the next section, Spark SQL queries can run directly on a directory of data, for delta use the following syntax:
SELECT * FROM delta./path/to/delta_directory
display(spark.sql("SELECT * FROM delta.`{}` LIMIT 5".format(DataPath)))
display(spark.sql("SELECT * FROM delta.`/mnt/training/delta/sample_csv/` LIMIT 5"))
CREATE A Table Using Delta Lake
Create a table called sample_data using DELTA out of the above data.
The notation is:
CREATE TABLE <table-name> USING DELTA LOCATION <path-do-data>
Tables created with a specified LOCATION are considered unmanaged by the metastore. Unlike a managed table, where no path is specified, an unmanaged table’s files are not deleted when you DROP the table. However, changes to either the registered table or the files will be reflected in both locations.
Managed tables require that the data for your table be stored in DBFS. Unmanaged tables only store metadata in DBFS.
Since Delta Lake stores schema (and partition) info in the _delta_log directory, we do not have to specify partition columns!
spark.sql("""
DROP TABLE IF EXISTS sample_data
""")
spark.sql("""
CREATE TABLE sample_data
USING DELTA
LOCATION '{}'
""".format(DataPath))
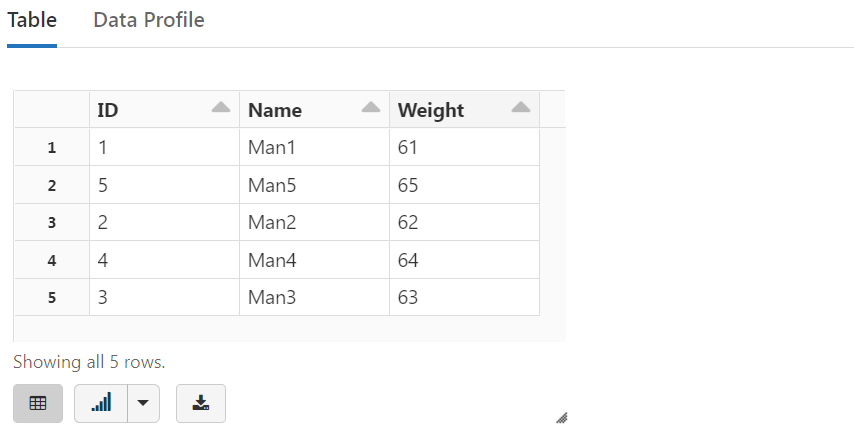
%sql SELECT count(*) FROM sample_data
Metadata
Since we already have data backing customer_data_delta in place, the table in the Hive metastore automatically inherits the schema, partitioning, and table properties of the existing data.
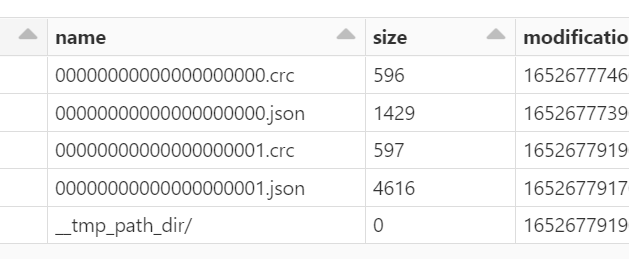
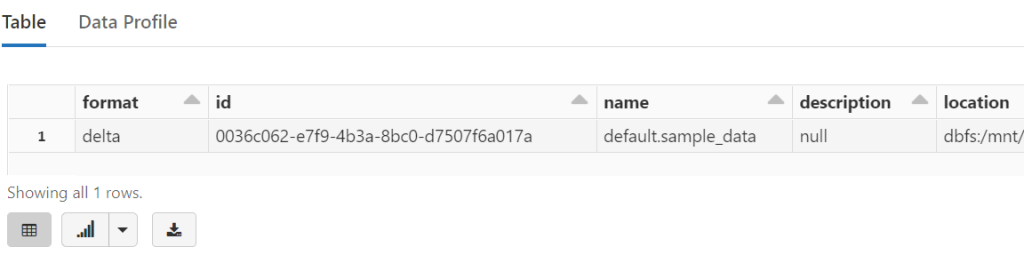
Note that we only store table name, path, database info in the Hive metastore, the actual schema is stored in the _delta_log directory as shown below.
display(dbutils.fs.ls(DataPath + "/_delta_log"))
Metadata is displayed through DESCRIBE DETAIL <tableName>.
As long as we have some data in place already for a Delta Lake table, we can infer schema.
%sql DESCRIBE DETAIL sample_data
Key Takeaways
Saving to Delta Lake is as easy as saving to Parquet, but creates an additional log file.
Using Delta Lake to create tables is straightforward and you do not need to specify schemas.
2. Delta Lake Batch Operations – Append
In this section, we’ll load a small amount of new data and show how easy it is to append this to our existing Delta table.
inputPath2 = "/mnt/training/sample2.tsv"
newDataDF = (spark
.read
.option("header", "true")
.option("sep", "\t")
.schema(inputSchema)
.csv(inputPath2)
)
Do a simple count of number of new items to be added to production data.
newDataDF.count()
display(newDataDF)
APPEND Using Delta Lake
Adding to our existing Delta Lake is as easy as modifying our write statement and specifying the append mode.
(newDataDF
.write
.format("delta")
.partitionBy("Name")
.mode("append")
.save(DataPath)
)
Perform a simple count query to verify the number of records and notice it is correct.
The changes to our files have been immediately reflected in the table that we’ve registered.
%sql SELECT count(*) FROM sample_data
create กับ append คนละ session บางทีข้อมูลเดิมหาย!?!
Key Takeaways
With Delta Lake, you can easily append new data without schema-on-read issues.
Changes to Delta Lake files will immediately be reflected in registered Delta tables.
3. Delta Lake Batch Operations – Upsert
To UPSERT means to “UPdate” and “inSERT”. In other words, UPSERT is literally TWO operations. It is not supported in traditional data lakes, as running an UPDATE could invalidate data that is accessed by the subsequent INSERT operation.
Using Delta Lake, however, we can do UPSERTS. Delta Lake combines these operations to guarantee atomicity to
- INSERT a row
- if the row already exists, UPDATE the row.
inputPath3 = "/mnt/training/sample3.tsv"
upsertDF = (spark
.read
.option("header", "true")
.option("sep", "\t")
.schema(inputSchema)
.csv(inputPath3)
)
display(upsertDF)
We’ll register this as a temporary view so that this table doesn’t persist in DBFS (but we can still use SQL to query it).
upsertDF.createOrReplaceTempView("upsert_data")
%sql SELECT * FROM upsert_data
We can use UPSERT to simultaneously INSERT our new data and UPDATE our previous records.
%sql MERGE INTO sample_data -- Delta table USING upsert_data -- another table ON sample_data.ID = upsert_data.ID -- AND WHEN MATCHED THEN UPDATE SET * WHEN NOT MATCHED THEN INSERT *
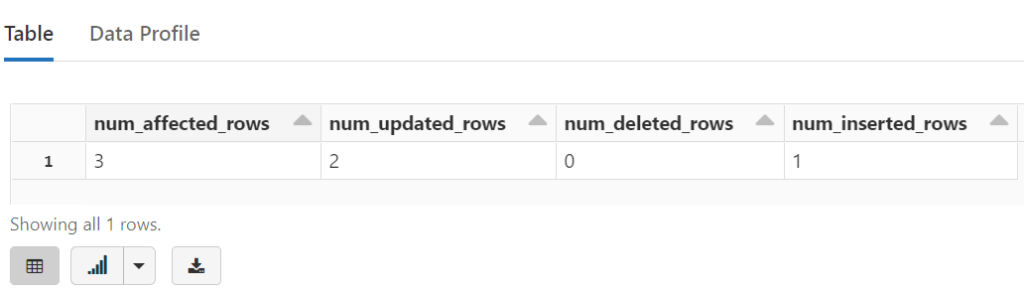
Notice how this data is seamlessly incorporated into sample_data
%sql SELECT * FROM sample_data ORDER BY ID
Upsert syntax
Upserting, or merging, in Delta Lake provides fine-grained updates of your data. The following syntax shows how to perform an Upsert:
MERGE INTO customers -- Delta table
USING updates
ON customers.customerId = source.customerId
WHEN MATCHED THEN
UPDATE SET address = updates.address
WHEN NOT MATCHED
THEN INSERT (customerId, address) VALUES (updates.customerId, updates.address)
See update table data syntax documentation.
Additional Topics & Resources
4. Merge ด้วย Python
เดิมอ่านตารางมาเป็น dataframe
tempDF = spark.read.table("sample_data")
คราวนี้อ่านมาเป็น Delta Table
- NameError: name ‘DeltaTable’ is not defined
pip install delta-spark
from delta.tables import * deltaTable = DeltaTable.forPath(spark, "/mnt/training/delta/sample_csv/")
เตรียมข้อมูลใหม่ที่จะนำมา merge
inputPath4 = "/mnt/training/sample4.tsv"
newData = (spark
.read
.option("header", "true")
.option("sep", "\t")
.schema(inputSchema)
.csv(inputPath4)
)
newData.createOrReplaceTempView("new_data")
สั่ง Merge โดย update และ insert เฉพาะคอลัมน์ name
from pyspark.sql.functions import col
deltaTable.alias("sample_data") \
.merge(
newData.alias("new_data"),
"sample_data.id = new_data.id") \
.whenMatchedUpdate(set = { "name": col("new_data.name") }) \
.whenNotMatchedInsert(values = { "name": col("new_data.name") }) \
.execute()
deltaTable.toDF().show()
คอลัมน์ Weight จะไม่มีการ update และถ้ามีการ insert ก็จะมีค่าเป็น null
%sql SELECT * FROM sample_data ORDER BY ID DESC
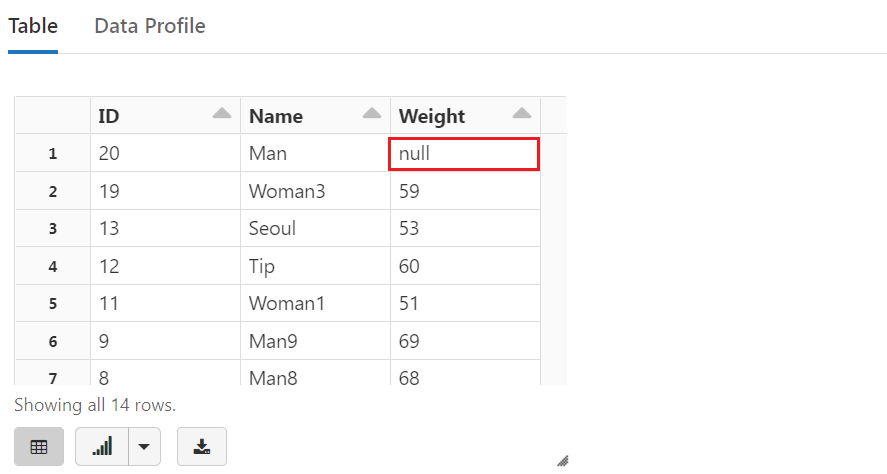
แต่ถ้าแบบนี้จะ update และ insert ทุกคอลัมน์
from pyspark.sql.functions import col
deltaTable.alias("sample_data") \
.merge(
newData.alias("new_data"),
"sample_data.id = new_data.id") \
.whenMatchedUpdateAll() \
.whenNotMatchedInsertAll() \
.execute()
deltaTable.toDF().show()