
- ตรวจสอบไฟล์ข้อมูล
- Reading from CSV – InferSchema
- Reading from CSV – User-Defined Schema
- Reading from multiple CSV
1. ตรวจสอบไฟล์ข้อมูล
We can use %fs ls … to view the file on the DBFS.
%fs ls /mnt/training/
We can use %fs head … to peek at the first couple thousand characters of the file.
%fs head /mnt/training/sample.tsv
ID Name Weight 1 Man1 61 2 Man2 62 3 Man3 63 4 Man4 64 5 Man5 65 6 Man6 66 7 Man7 67 8 Man8 68 9 Man9 69
2. Reading from CSV – InferSchema
Step #1 – Read The CSV File
Let’s start with the bare minimum by specifying the tab character as the delimiter and the location of the file:
# A reference to our tab-separated-file
csvFile = "/mnt/training/sample.tsv"
tempDF = (spark.read # The DataFrameReader
.option("sep", "\t") # Use tab delimiter (default is comma-separator)
.csv(csvFile) # Creates a DataFrame from CSV after reading in the file
)
This is guaranteed to trigger one job. A Job is triggered anytime we are “physically” required to touch the data. In some cases, one action may create multiple jobs (multiple reasons to touch the data). In this case, the reader has to “peek” at the first line of the file to determine how many columns of data we have.
We can see the structure of the DataFrame by executing the command printSchema()
tempDF.printSchema()
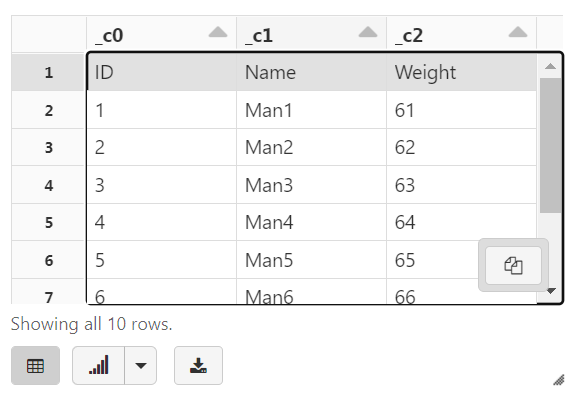
root |-- _c0: string (nullable = true) |-- _c1: string (nullable = true) |-- _c2: string (nullable = true)
the column names _c0, _c1, and _c2 (automatically generated names)
display(tempDF)
Step #2 – Use the File’s Header
tempDF2 = (spark.read # The DataFrameReader
.option("sep", "\t") # Use tab delimiter (default is comma-separator)
.option("header", "true") # Use first line of all files as header
.csv(csvFile) # Creates a DataFrame from CSV after reading in the file
)
tempDF2.printSchema()
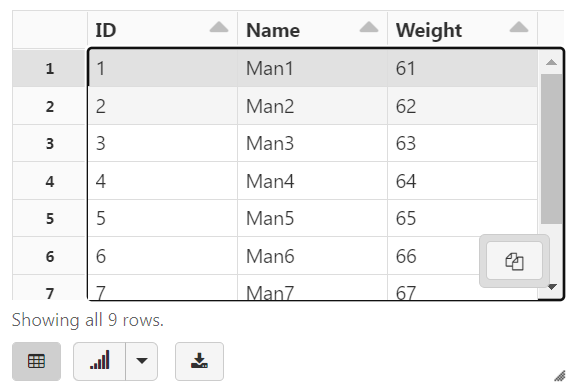
root |-- ID: string (nullable = true) |-- Name: string (nullable = true) |-- Weight: string (nullable = true)
display(tempDF2)
Step #3 – Infer the Schema
Lastly, we can add an option that tells the reader to infer each column’s data type (aka the schema)
tempDF3 = (spark.read # The DataFrameReader
.option("header", "true") # Use first line of all files as header
.option("sep", "\t") # Use tab delimiter (default is comma-separator)
.option("inferSchema", "true") # Automatically infer data types
.csv(csvFile) # Creates a DataFrame from CSV after reading in the file
)
tempDF3.printSchema()
root |-- ID: integer (nullable = true) |-- Name: string (nullable = true) |-- Weight: integer (nullable = true)
Two Spark jobs were executed (not one as in the previous example)
3. Reading from CSV – User-Defined Schema
The difference here is that we are going to define the schema beforehand and hopefully avoid the execution of any extra jobs.
Step #1
Declare the schema. This is just a list of field names and data types.
# Required for StructField, StringType, IntegerType, etc.
from pyspark.sql.types import *
csvSchema = StructType([
StructField("ID", IntegerType(), False),
StructField("Name", StringType(), False),
StructField("Weight", IntegerType(), False)
])
Step #2
Read in our data (and print the schema). We can specify the schema, or rather the StructType, with the schema(..) command:
tempDF4 = (spark.read # The DataFrameReader
.option('header', 'true') # Ignore line #1 - it's a header
.option('sep', "\t") # Use tab delimiter (default is comma-separator)
.schema(csvSchema) # Use the specified schema
.csv(csvFile) # Creates a DataFrame from CSV after reading in the file
)
tempDF4.printSchema()
root |-- ID: integer (nullable = true) |-- Name: string (nullable = true) |-- Weight: integer (nullable = true)
Zero Spark jobs were executed
4. Reading from multiple CSV
tempDF = (spark.read
.option("header", "true")
.csv("/mnt/training/*.csv")
)
tempDF = (spark.read
.format("csv")
.option("header", "true")
.load("/mnt/training/*.csv")
)