- ตรวจสอบไฟล์ข้อมูล
- Reading from JSON – InferSchema
- Reading from JSON – User-Defined Schema
1. ตรวจสอบไฟล์ข้อมูล
We can use %fs ls … to view the file on the DBFS.
%fs ls dbfs:/mnt/training/sample.json
We can use %fs head … to peek at the first couple thousand characters of the file.
%fs head /mnt/training/sample.json
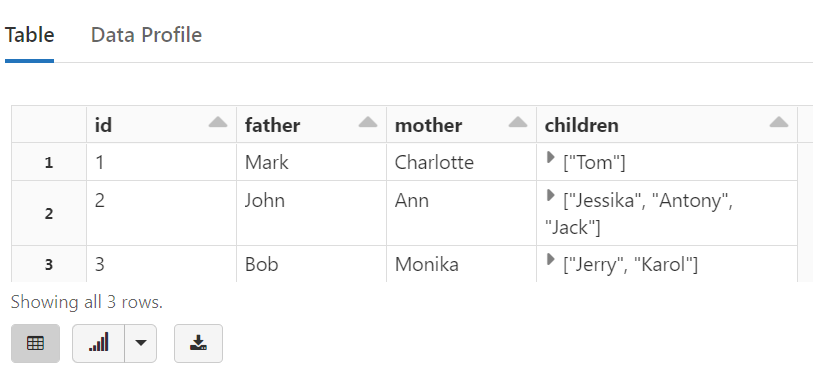
{"id":1,"father":"Mark","mother":"Charlotte","children":["Tom"]}
{"id":2,"father":"John","mother":"Ann","children":["Jessika","Antony","Jack"]}
{"id":3,"father":"Bob","mother":"Monika","children":["Jerry","Karol"]}
และ
%fs head /mnt/training/sample2.json
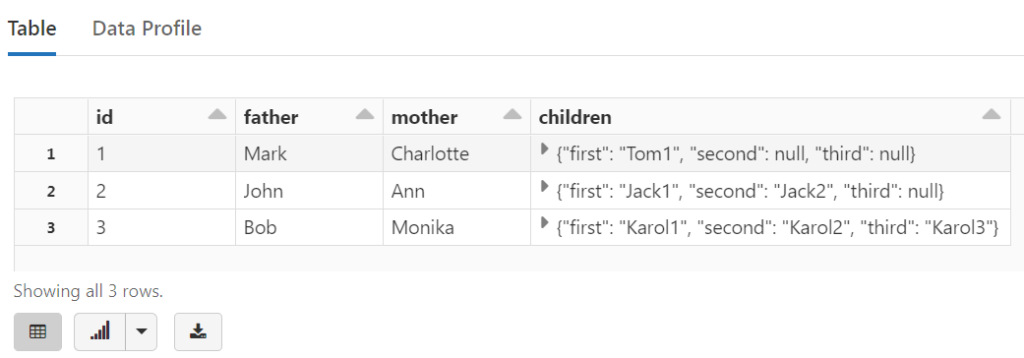
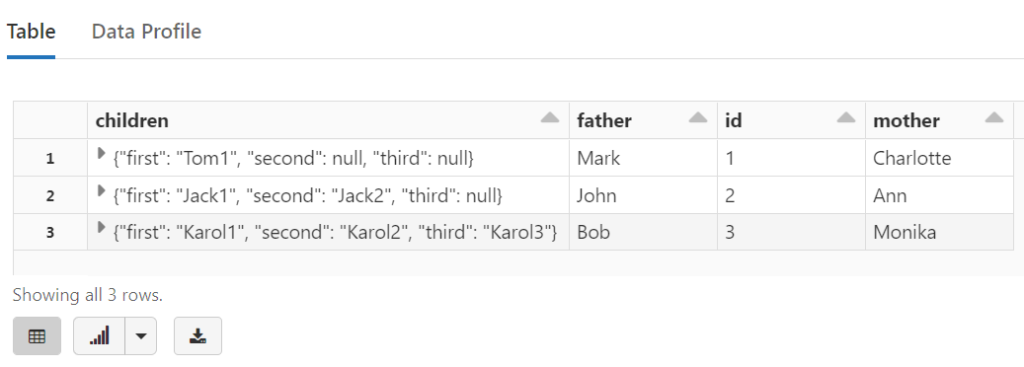
{"id":1,"father":"Mark","mother":"Charlotte","children":{"first":"Tom1"}}
{"id":2,"father":"John","mother":"Ann","children":{"first":"Jack1","second":"Jack2"}}
{"id":3,"father":"Bob","mother":"Monika","children":{"first":"Karol1","second":"Karol2","third":"Karol3"}}
CREATE OR REPLACE TEMP VIEW tmp_json AS SELECT * FROM JSON.`path/to/file.json`
2. Reading from JSON – InferSchema
JSON Lines
- That there is one JSON object per line and…
- That it’s delineated by a new-line.
This format is referred to as JSON Lines or newline-delimited JSON. More information about this format can be found at http://jsonlines.org.
** Note: ** Spark 2.2 was released on July 11th 2016. With that comes File IO improvements for CSV & JSON, but more importantly, Support for parsing multi-line JSON and CSV files. You can read more about that (and other features in Spark 2.2) in the Databricks Blog.
Read The JSON File ตัวอย่าง 1
The command to read in JSON looks very similar to that of CSV.
jsonFile = "/mnt/training/sample.json"
tempDF = (spark.read # The DataFrameReader
.option("inferSchema", "true") # Automatically infer data types & column names
.json(jsonFile) # Creates a DataFrame from CSV after reading in the file
)
tempDF.printSchema()
root |-- children: array (nullable = true) | |-- element: string (containsNull = true) |-- father: string (nullable = true) |-- id: long (nullable = true) |-- mother: string (nullable = true)
With our DataFrame created, we can now take a peak at the data. But to demonstrate a unique aspect of JSON data (or any data with embedded fields), we will first create a temporary view and then view the data via SQL:
# create a view called temp_view
tempDF.createOrReplaceTempView("temp_view")
And now we can take a peak at the data with simple SQL SELECT statement:
%sql SELECT * FROM temp_view
%sql SELECT id, father, mother, children FROM temp_view
Read The JSON File ตัวอย่าง 2
jsonFile2 = "/mnt/training/sample2.json"
tempDF2 = (spark.read # The DataFrameReader
.option("inferSchema", "true") # Automatically infer data types & column names
.json(jsonFile2) # Creates a DataFrame from CSV after reading in the file
)
tempDF2.printSchema()
root |-- children: struct (nullable = true) | |-- first: string (nullable = true) | |-- second: string (nullable = true) | |-- third: string (nullable = true) |-- father: string (nullable = true) |-- id: long (nullable = true) |-- mother: string (nullable = true)
# create a view called temp_view2
tempDF2.createOrReplaceTempView("temp_view2")
%sql SELECT * FROM temp_view2
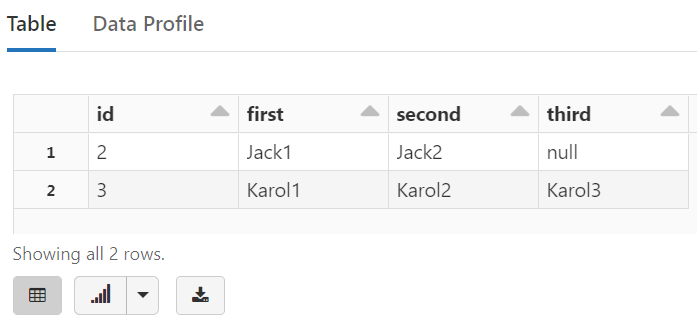
%sql SELECT id, children.first, children.second, children.third FROM temp_view2 WHERE children.second IS NOT NULL
Review: Reading from JSON – InferSchema
- We only need one job even when inferring the schema.
- There is no header which is why there isn’t a second job in this case – the column names are extracted from the JSON object’s attributes.
3. Reading from JSON – User-Defined Schema
To avoid the extra job, we can (just like we did with CSV) specify the schema for the DataFrame.
ตัวอย่าง 1 Step #1 – Create the Schema
Note that we can support complex data types as seen in the field children.
# Required for StructField, StringType, IntegerType, etc.
from pyspark.sql.types import *
jsonSchema = StructType([
StructField("id", LongType(), True),
StructField("father", StringType(), True),
StructField("mother", StringType(), True),
StructField("children", ArrayType(StringType()), True)
])
For a small file, manually creating the the schema may not be worth the effort. However, for a large file, the time to manually create the schema may be worth the trade off of a really long infer-schema process.
ตัวอย่าง 1 Step #2 – Read in the JSON
Next, we will read in the JSON file and print its schema.
(spark.read # The DataFrameReader .schema(jsonSchema) # Use the specified schema .json(jsonFile) # Creates a DataFrame from JSON after reading in the file .printSchema() )
root |-- id: long (nullable = true) |-- father: string (nullable = true) |-- mother: string (nullable = true) |-- children: array (nullable = true) | |-- element: string (containsNull = true)
ตัวอย่าง 2 Step #1 – Create the Schema
# Required for StructField, StringType, IntegerType, etc.
from pyspark.sql.types import *
jsonSchema2 = StructType([
StructField("id", LongType(), True),
StructField("father", StringType(), True),
StructField("mother", StringType(), True),
StructField("children", StructType([
StructField("first", StringType(), True),
StructField("second", StringType(), True),
StructField("third", StringType(), True)
]), True),
])
ตัวอย่าง 2 Step #2 – Read in the JSON
(spark.read # The DataFrameReader .schema(jsonSchema2) # Use the specified schema .json(jsonFile2) # Creates a DataFrame from JSON after reading in the file .printSchema() )
root |-- id: long (nullable = true) |-- father: string (nullable = true) |-- mother: string (nullable = true) |-- children: struct (nullable = true) | |-- first: string (nullable = true) | |-- second: string (nullable = true) | |-- third: string (nullable = true)
Review: Reading from JSON – User-Defined Schema
- Just like CSV, providing the schema avoids the extra jobs.
- The schema allows us to rename columns and specify alternate data types.
คำสั่ง display()
tempDF2 = (spark.read .schema(jsonSchema2) .json(jsonFile2) )
display(tempDF2)