- Work with DataFrames in Azure Databricks – Learn | Microsoft Docs
- Overview – Spark 3.2.1 Documentation (apache.org)
- Create a DataFrame
- count()
- cache() & persist()
- show(..)
- display(..)
- limit(..)
- select(..)
- drop(..)
- distinct() & dropDuplicates()
- dropDuplicates(columns…)
- filter()
- DataFrames vs SQL & Temporary Views
1. Create a DataFrame
- We can read the Parquet files into a
DataFrame. - We’ll start with the object
spark, an instance ofSparkSessionand the entry point to Spark 2.0 applications. - From there we can access the
readobject which gives us an instance ofDataFrameReader.
ใช้ตัวอย่างไฟล์ parquet จาก Read data in Parquet format
parquetDir = "/mnt/training/sample_parquet/"
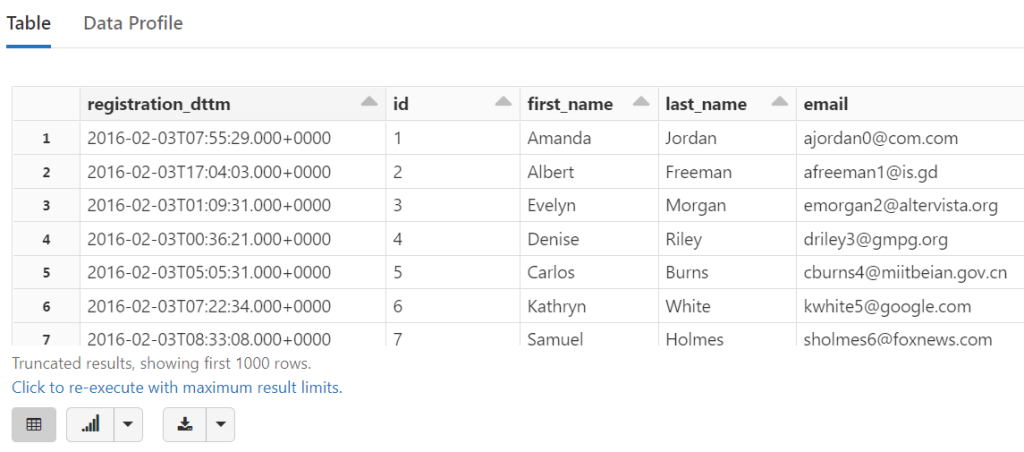
tempDF = (spark # Our SparkSession & Entry Point .read # Our DataFrameReader .parquet(parquetDir) # Returns an instance of DataFrame ) print(tempDF) # Python hack to see the data type
DataFrame[registration_dttm: timestamp, id: int, first_name: string, last_name: string, email: string, gender: string, ip_address: string, cc: string, country: string, birthdate: string, salary: double, title: string, comments: string]
2. count()
If you look at the API docs, count() is described like this: “Returns the number of rows in the Dataset.” count() will trigger a job to process the request and return a value.
We can now count all records in our DataFrame like this:
total = tempDF.count()
print("Record Count: {0:,}".format( total ))
Record Count: 5,000
3. cache() & persist()
The ability to cache data is one technique for achieving better performance with Apache Spark.
This is because every action requires Spark to read the data from its source (Azure Blob, Amazon S3, HDFS, etc.) but caching moves that data into the memory of the local executor for “instant” access.
cache() is just an alias for persist().
(tempDF .cache() # Mark the DataFrame as cached .count() # Materialize the cache )
If you re-run that command, it should take significantly less time.
total = tempDF.count()
print("Record Count: {0:,}".format( total ))
Performance considerations of Caching Data
When Caching Data you are placing it on the workers of the cluster.
Caching takes resources, before moving a notebook into production please check and verify that you are appropriately using cache.
And as a quick side note, you can remove a cache by calling the DataFrame‘s unpersist() method but, it is not necessary.
4. show(..)
show() is a function that will allow us to print the data to the console. In the case of Python, we have one method with two optional parameters.
show(..) method effectively has two optional parameters:
- n: The number of records to print to the console, the default being 20.
- truncate: If true, columns wider than 20 characters will be truncated, where the default is true.
tempDF.show()
tempDF.show(2, True)
+-------------------+---+----------+---------+----------------+------+--------------+----------------+---------+---------+---------+----------------+--------+ | registration_dttm| id|first_name|last_name| email|gender| ip_address| cc| country|birthdate| salary| title|comments| +-------------------+---+----------+---------+----------------+------+--------------+----------------+---------+---------+---------+----------------+--------+ |2016-02-03 07:55:29| 1| Amanda| Jordan|ajordan0@com.com|Female| 1.197.201.2|6759521864920116|Indonesia| 3/8/1971| 49756.53|Internal Auditor| 1E+02| |2016-02-03 17:04:03| 2| Albert| Freeman| afreeman1@is.gd| Male|218.111.175.34| | Canada|1/16/1968|150280.17| Accountant IV| | +-------------------+---+----------+---------+----------------+------+--------------+----------------+---------+---------+---------+----------------+--------+ only showing top 2 rows
Note: The function show(..) is an action which triggers a job.
5. display(..)
Instead of calling show(..) on an existing DataFrame we can instead pass our DataFrame to the display(..) command:
display(tempDF)
show(..) vs display(..)
show(..)is part of core spark –display(..)is specific to our notebooks.show(..)is ugly –display(..)is pretty.show(..)has parameters for truncating both columns and rows –display(..)does not.show(..)is a function of theDataFrame/Datasetclass –display(..)works with a number of different objects.display(..)is more powerful – with it, you can…- Download the results as CSV
- Render line charts, bar chart & other graphs, maps and more.
- See up to 1000 records at a time.
display(..) is an action which triggers a job.
6. limit(..)
limit(..) is described like this: “Returns a new Dataset by taking the first n rows…“
show(..), like many actions, does not return anything. On the other hand, transformations like limit(..) return a new DataFrame:
limitedDF = tempDF.limit(5) # "limit" the number of records to the first 5 limitedDF # Python hack to force printing of the data type
Out[26]: DataFrame[registration_dttm: timestamp, id: int, first_name: string, last_name: string, email: string, gender: string, ip_address: string, cc: string, country: string, birthdate: string, salary: double, title: string, comments: string]
Nothing Happened
- Notice how “nothing” happened – that is no job was triggered.
- This is because we are simply defining the second step in our transformations.
- Read in the parquet file (represented by tempDF).
- Limit those records to just the first 5 (represented by limitedDF).
- It’s not until we induce an action that a job is triggered and the data is processed
7. select(..)
The select(..) command is one of the most powerful and most commonly used transformations.
select(..) is described like this: “Returns a new Dataset by computing the given Column expression for each element.“
Just like limit(..), select(..)
- does not trigger a job
- returns a new
DataFrame - simply defines the next transformation in a sequence of transformations.
# Transform the data by selecting only three columns
onlyThreeDF = (tempDF
.select("id", "first_name", "email")
)
# Now let's take a look at what the schema looks like
onlyThreeDF.printSchema()
root |-- id: integer (nullable = true) |-- first_name: string (nullable = true) |-- email: string (nullable = true)
onlyThreeDF.show(5, False)
+---+----------+------------------------+ |id |first_name|email | +---+----------+------------------------+ |1 |Amanda |ajordan0@com.com | |2 |Albert |afreeman1@is.gd | |3 |Evelyn |emorgan2@altervista.org | |4 |Denise |driley3@gmpg.org | |5 |Carlos |cburns4@miitbeian.gov.cn| +---+----------+------------------------+ only showing top 5 rows
8. drop(..)
Instead of selecting everything we wanted, drop(..) allows us to specify the columns we don’t want.
drop(..) is described like this: “Returns a new Dataset with a column dropped.“
# Transform the data by drop some column
droppedDF = (tempDF
.drop("registration_dttm")
)
# Now let's take a look at what the schema looks like
droppedDF.printSchema()
Again, drop(..) is just one more transformation – that is no job is triggered.
9. distinct() & dropDuplicates()
These two transformations do the same thing. In fact, they are aliases for one another.
- You can see this by looking at the source code for these two methods
def distinct(): Dataset[T] = dropDuplicates()- See Dataset.scala
distinct(..) and dropDuplicates(..) are described like this: “Returns a new Dataset that contains only the unique rows from this Dataset….“
distinctDF = (pagecountsEnAllDF # Our original DataFrame
.select("gender") # Drop all columns except the "gender" column
.distinct() # Reduce the set of all records to just the distinct column.
)
distinctDF = pagecountsEnAllDF.distinct()
print("Distinct count: " + str(distinctDF.count()))
display(distinctDF)
total = distinctDF.count()
print("Distinct Projects: {0:,}".format( total ))
Distinct Projects: 3
10. dropDuplicates(columns…)
The method dropDuplicates(..) has a second variant that accepts one or more columns.
- The distinction is not performed across the entire record unlike
distinct()or evendropDuplicates(). - The distinction is based only on the specified columns.
- This allows us to keep all the original columns in our
DataFrame.
11. filter()
กรณีนี้ จะไม่เอา row ที่ คอลัมน์ Name มีค่า product4
df2 = df.filter(df.Name != 'product4')
12. DataFrames vs SQL & Temporary Views
The DataFrames API is built upon an SQL engine.
As such we can “convert” a DataFrame into a temporary view (or table) and then use it in “standard” SQL.
Let’s start by creating a temporary view from a previous DataFrame.
tempDF.createOrReplaceTempView("family")
Now that we have a temporary view (or table) we can start expressing our queries and transformations in SQL:
%sql SELECT * FROM family
And we can just as easily express in SQL the distinct list of projects, and just because we can, we’ll sort that list:
%sql SELECT DISTINCT gender FROM family ORDER BY gender
And converting from SQL back to a DataFrame is just as easy:
tableDF = spark.sql("SELECT DISTINCT gender FROM family ORDER BY gender")
display(tableDF)