- sql – Can you create nested WITH clauses for Common Table Expressions? – Stack Overflow
- Subqueries | BigQuery | Google Cloud
WITH
x AS
(
SELECT * FROM MyTable
),
y AS
(
SELECT * FROM x
)
SELECT * FROM y

WITH
x AS
(
SELECT * FROM MyTable
),
y AS
(
SELECT * FROM x
)
SELECT * FROM y
screen_view (event_params)
SELECT user_pseudo_id, (SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id') AS ga_session_id, (SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'firebase_previous_id') AS firebase_previous_id, (SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'firebase_screen_id') AS firebase_screen_id, (SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'firebase_previous_screen') AS firebase_previous_screen, (SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'firebase_screen') AS firebase_screen, (SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'firebase_previous_class') AS firebase_previous_class, (SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'firebase_screen_class') AS firebase_screen_class, FROM `my_project.my_dataset.events_*` WHERE event_name = 'screen_view' AND _TABLE_SUFFIX BETWEEN '20220901' AND '20220901' ORDER BY ga_session_id, event_timestamp
แสดงทุก screen , แสดงคู่ firebase_previous_screen และ firebase_screen
SELECT
firebase_previous_screen,
firebase_screen,
COUNT(*) AS cnt
FROM
(
SELECT
(SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'firebase_previous_screen') AS firebase_previous_screen,
(SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'firebase_screen') AS firebase_screen,
FROM
`my_project.my_dataset.events_*`
WHERE
event_name = 'screen_view'
AND _TABLE_SUFFIX BETWEEN '20220901' AND '20220901'
)
GROUP BY
firebase_previous_screen,
firebase_screen
ORDER BY
firebase_screen
+--------------------------+-----------------+-----+ | firebase_previous_screen | firebase_screen | cnt | +--------------------------+-----------------+-----+ | ScreenA | ScreenB | 10 | | ScreenB | ScreenC | 5 | | ScreenD | ScreenE | 1 | +--------------------------+-----------------+-----+
เลือกเฉพาะ screen จาก session ที่มี screen ที่กำหนดเท่านั้น (เช่น ใน session นั้นๆมี ‘ScreenA’ หรือ ‘ScreenB’ ก็แสดงทุก screen ใน session นั้น)
WITH table_screen_view AS
(
SELECT
user_pseudo_id,
event_timestamp,
(SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id') AS ga_session_id,
(SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'firebase_previous_screen') AS firebase_previous_screen,
(SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'firebase_screen') AS firebase_screen,
FROM
`my_project.my_dataset.events_*`
WHERE
event_name = 'screen_view'
AND _TABLE_SUFFIX BETWEEN '20220901' AND '20220901'
)
SELECT
firebase_previous_screen,
firebase_screen,
COUNT(*) AS cnt,
FROM table_screen_view
WHERE
ga_session_id IN ( SELECT ga_session_id
FROM table_screen_view
WHERE firebase_screen IN ('ScreenA', 'ScreenB')
)
GROUP BY
firebase_previous_screen,
firebase_screen
ORDER BY
firebase_screen
+--------------------------+-----------------+-----+ | firebase_previous_screen | firebase_screen | cnt | +--------------------------+-----------------+-----+ | ScreenA | ScreenB | 10 | | ScreenB | ScreenC | 5 | +--------------------------+-----------------+-----+
แสดงทุก screen (firebase_screen) ใน session เดียวกัน โดยเรียงจาก event_timestamp
WITH sequence_screen AS
(
SELECT
ga_session_id,
firebase_screen,
concat('stage', cast(stage_rank as string)) AS stage_rank,
FROM
(
SELECT
ga_session_id,
firebase_screen,
RANK() OVER (PARTITION BY ga_session_id ORDER BY event_timestamp ASC) AS stage_rank,
FROM
(
SELECT
event_timestamp,
(SELECT value.int_value FROM UNNEST(event_params) WHERE key = 'ga_session_id') AS ga_session_id,
(SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'firebase_screen') AS firebase_screen,
FROM
`my_project.my_dataset.events_*`
WHERE
event_name = 'screen_view'
AND _TABLE_SUFFIX BETWEEN '20220901' AND '20220901'
)
)
)
SELECT * FROM sequence_screen
PIVOT(any_value(firebase_screen) FOR stage_rank IN ('stage1', 'stage2', 'stage3', 'stage4', 'stage5'))
ORDER BY ga_session_id
+-------------------------+---------+---------+---------+---------+ | ga_session_id | stage1 | stage2 | stage3 | stage4 | stage5 | +-------------------------+---------+---------+---------+---------+ | 1234567891 | ScreenA | ScreenB | ScreenC | ScreenD | ScreenE | | 1234567892 | ScreenA | ScreenC | ScreenD | NULL | NULL | +-------------------------+---------+---------+---------+---------+
Wildcard tables enable you to query multiple tables using concise SQL statements. Wildcard tables are available only in standard SQL. For equivalent functionality in legacy SQL, see Table wildcard functions.
A wildcard table represents a union of all the tables that match the wildcard expression.
# Standard SQL SELECT * FROM `my_project.my_dataset.my_table_202208*`
Each row in the wildcard table contains a special column, _TABLE_SUFFIX, which contains the value matched by the wildcard character.
For information on wildcard table syntax, see Wildcard tables in the standard SQL reference.
# Standard SQL SELECT * FROM `my_project.my_dataset.my_table_*` WHERE _TABLE_SUFFIX BETWEEN '20220801' AND '20220831'
RANK()
OVER over_clause
over_clause:
{ named_window | ( [ window_specification ] ) }
window_specification:
[ named_window ]
[ PARTITION BY partition_expression [, ...] ]
ORDER BY expression [ { ASC | DESC } ] [, ...]
Example1
WITH Numbers AS (SELECT 1 as x UNION ALL SELECT 2 UNION ALL SELECT 2 UNION ALL SELECT 5 UNION ALL SELECT 8 UNION ALL SELECT 10 UNION ALL SELECT 10 ) SELECT x, RANK() OVER (ORDER BY x ASC) AS rank FROM Numbers
+-------------------------+ | x | rank | +-------------------------+ | 1 | 1 | | 2 | 2 | | 2 | 2 | | 5 | 4 | | 8 | 5 | | 10 | 6 | | 10 | 6 | +-------------------------+
Example2
WITH finishers AS (SELECT 'Sophia Liu' as name, TIMESTAMP '2016-10-18 2:51:45' as finish_time, 'F30-34' as division UNION ALL SELECT 'Lisa Stelzner', TIMESTAMP '2016-10-18 2:54:11', 'F35-39' UNION ALL SELECT 'Nikki Leith', TIMESTAMP '2016-10-18 2:59:01', 'F30-34' UNION ALL SELECT 'Lauren Matthews', TIMESTAMP '2016-10-18 3:01:17', 'F35-39' UNION ALL SELECT 'Desiree Berry', TIMESTAMP '2016-10-18 3:05:42', 'F35-39' UNION ALL SELECT 'Suzy Slane', TIMESTAMP '2016-10-18 3:06:24', 'F35-39' UNION ALL SELECT 'Jen Edwards', TIMESTAMP '2016-10-18 3:06:36', 'F30-34' UNION ALL SELECT 'Meghan Lederer', TIMESTAMP '2016-10-18 2:59:01', 'F30-34') SELECT name, finish_time, division, RANK() OVER (PARTITION BY division ORDER BY finish_time ASC) AS finish_rank FROM finishers;
+-----------------+------------------------+----------+-------------+ | name | finish_time | division | finish_rank | +-----------------+------------------------+----------+-------------+ | Sophia Liu | 2016-10-18 09:51:45+00 | F30-34 | 1 | | Meghan Lederer | 2016-10-18 09:59:01+00 | F30-34 | 2 | | Nikki Leith | 2016-10-18 09:59:01+00 | F30-34 | 2 | | Jen Edwards | 2016-10-18 10:06:36+00 | F30-34 | 4 | | Lisa Stelzner | 2016-10-18 09:54:11+00 | F35-39 | 1 | | Lauren Matthews | 2016-10-18 10:01:17+00 | F35-39 | 2 | | Desiree Berry | 2016-10-18 10:05:42+00 | F35-39 | 3 | | Suzy Slane | 2016-10-18 10:06:24+00 | F35-39 | 4 | +-----------------+------------------------+----------+-------------+
FROM from_item[, ...] unpivot_operator
unpivot_operator:
UNPIVOT [ { INCLUDE NULLS | EXCLUDE NULLS } ] (
{ single_column_unpivot | multi_column_unpivot }
) [unpivot_alias]
single_column_unpivot:
values_column
FOR name_column
IN (columns_to_unpivot)
multi_column_unpivot:
values_column_set
FOR name_column
IN (column_sets_to_unpivot)
values_column_set:
(values_column[, ...])
columns_to_unpivot:
unpivot_column [row_value_alias][, ...]
column_sets_to_unpivot:
(unpivot_column [row_value_alias][, ...])
unpivot_alias and row_value_alias:
[AS] alias
The UNPIVOT operator rotates columns into rows. UNPIVOT is part of the FROM clause.
UNPIVOT can be used to modify any table expression.UNPIVOT with FOR SYSTEM_TIME AS OF is not allowed, although users may use UNPIVOT against a subquery input which itself uses FOR SYSTEM_TIME AS OF.WITH OFFSET clause immediately preceding the UNPIVOT operator is not allowed.PIVOT aggregations cannot be reversed with UNPIVOT.WITH Produce AS ( SELECT 'Kale' as product, 51 as Q1, 23 as Q2, 45 as Q3, 3 as Q4 UNION ALL SELECT 'Apple', 77, 0, 25, 2) SELECT * FROM Produce
+---------+----+----+----+----+ | product | Q1 | Q2 | Q3 | Q4 | +---------+----+----+----+----+ | Kale | 51 | 23 | 45 | 3 | | Apple | 77 | 0 | 25 | 2 | +---------+----+----+----+----+
SELECT * FROM Produce UNPIVOT(sales FOR quarter IN (Q1, Q2, Q3, Q4))
+---------+-------+---------+ | product | sales | quarter | +---------+-------+---------+ | Kale | 51 | Q1 | | Kale | 23 | Q2 | | Kale | 45 | Q3 | | Kale | 3 | Q4 | | Apple | 77 | Q1 | | Apple | 0 | Q2 | | Apple | 25 | Q3 | | Apple | 2 | Q4 | +---------+-------+---------+
The Pivot operation in Google BigQuery changes rows into columns by using Aggregation. Let’s understand the working of the Pivot operator with the help of a table containing information about Products and their Sales per Quarter. The following examples reference a table called Produce that looks like this before applying the Pivot operation:
Example1
WITH Produce AS ( SELECT 'Win' as product, 51 as sales, 'Q1' as quarter UNION ALL SELECT 'Win', 23, 'Q2' UNION ALL SELECT 'Win', 45, 'Q3' UNION ALL SELECT 'Win', 3, 'Q4' UNION ALL SELECT 'Linux', 77, 'Q1' UNION ALL SELECT 'Linux', 0, 'Q2' UNION ALL SELECT 'Linux', 25, 'Q3' UNION ALL SELECT 'Linux', 2, 'Q4') SELECT * FROM Produce
+---------+-------+---------+ | product | sales | quarter | +---------+-------+---------+ | Win | 51 | Q1 | | Win | 23 | Q2 | | Win | 45 | Q3 | | Win | 3 | Q4 | | Linux | 77 | Q1 | | Linux | 0 | Q2 | | Linux | 25 | Q3 | | Linux | 2 | Q4 | +---------+-------+---------+
After applying the Pivot operator, you can rotate the Sales and Quarter into Q1, Q2, Q3, and Q4 columns. This will make the table much more readable. The query for the same would look something like this:
SELECT * FROM
(SELECT * FROM Produce)
PIVOT(SUM(sales) FOR quarter IN ('Q1', 'Q2', 'Q3', 'Q4'))
+---------+----+----+----+----+ | product | Q1 | Q2 | Q3 | Q4 | +---------+----+----+----+----+ | Win | 51 | 23 | 45 | 3 | | Linux | 77 | 0 | 25 | 2 | +---------+----+----+----+----+
Example2
WITH `table_name` AS ( SELECT '1662104425' `ga_session_id`, 'page_a' AS `page`, 'r1' AS `rank` UNION ALL SELECT '1662104425', 'page_b', 'r2' UNION ALL SELECT '1662104425', 'page_c', 'r3' UNION ALL SELECT '1662104425', 'page_d', 'r4' UNION ALL SELECT '1662104425', 'page_e', 'r5' UNION ALL SELECT '1662091784', 'page_b', 'r1' UNION ALL SELECT '1662091784', 'page_c', 'r2' UNION ALL SELECT '1662091784', 'page_d', 'r3' ) SELECT * FROM table_name
| Row | ga_session_id | page | rank | |
|---|---|---|---|---|
| 1 | 1662104425 | page_a | r1 | |
| 2 | 1662104425 | page_b | r2 | |
| 3 | 1662104425 | page_c | r3 | |
| 4 | 1662104425 | page_d | r4 | |
| 5 | 1662104425 | page_e | r5 | |
| 6 | 1662091784 | page_b | r1 | |
| 7 | 1662091784 | page_c | r2 | |
| 8 | 1662091784 | page_d | r3 |
ใช้ ANY_VALUE
SELECT * FROM table_name
PIVOT(any_value(page) FOR rank IN ('r1', 'r2', 'r3', 'r4', 'r5'))
| Row | ga_session_id | r1 | r2 | r3 | r4 | r5 | |
|---|---|---|---|---|---|---|---|
| 1 | 1662104425 | page_a | page_b | page_c | page_d | page_e | |
| 2 | 1662091784 | page_b | page_c | page_d | null | null |
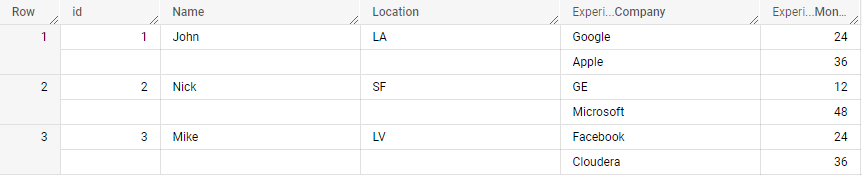
SELECT *
#standardSQL
WITH `table_name` AS (
SELECT 1 AS id, 'John' AS Name, 'LA' AS Location, [STRUCT<Company STRING, Months INT64>('Google', 24), ('Apple', 36)] AS Experience UNION ALL
SELECT 2, 'Nick', 'SF', [STRUCT<Company STRING, Months INT64>('GE', 12), ('Microsoft', 48)] AS Experience UNION ALL
SELECT 3, 'Mike', 'LV', [STRUCT<Company STRING, Months INT64>('Facebook', 24), ('Cloudera', 36)] AS Experience
)
SELECT * FROM `table_name`
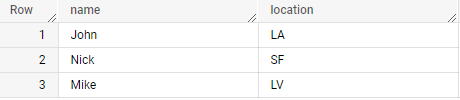
SELECT name, location
#standardSQL
WITH `table_name` AS (
SELECT 1 AS id, 'John' AS Name, 'LA' AS Location, [STRUCT<Company STRING, Months INT64>('Google', 24), ('Apple', 36)] AS Experience UNION ALL
SELECT 2, 'Nick', 'SF', [STRUCT<Company STRING, Months INT64>('GE', 12), ('Microsoft', 48)] AS Experience UNION ALL
SELECT 3, 'Mike', 'LV', [STRUCT<Company STRING, Months INT64>('Facebook', 24), ('Cloudera', 36)] AS Experience
)
SELECT name, location FROM `table_name`
WHERE NOT EXISTS
#standardSQL
WITH `table_name` AS (
SELECT 1 AS id, 'John' AS Name, 'LA' AS Location, [STRUCT<Company STRING, Months INT64>('Google', 24), ('Apple', 36)] AS Experience UNION ALL
SELECT 2, 'Nick', 'SF', [STRUCT<Company STRING, Months INT64>('GE', 12), ('Microsoft', 48)] AS Experience UNION ALL
SELECT 3, 'Mike', 'LV', [STRUCT<Company STRING, Months INT64>('Facebook', 24), ('Cloudera', 36)] AS Experience
)
SELECT name, location FROM `table_name`
WHERE NOT EXISTS (SELECT 1 FROM UNNEST(Experience) WHERE Company = 'GE')

WHERE EXISTS
#standardSQL
WITH `table_name` AS (
SELECT 1 AS id, 'John' AS Name, 'LA' AS Location, [STRUCT<Company STRING, Months INT64>('Google', 24), ('Apple', 36)] AS Experience UNION ALL
SELECT 2, 'Nick', 'SF', [STRUCT<Company STRING, Months INT64>('GE', 12), ('Microsoft', 48)] AS Experience UNION ALL
SELECT 3, 'Mike', 'LV', [STRUCT<Company STRING, Months INT64>('Facebook', 24), ('Cloudera', 36)] AS Experience
)
SELECT name, location FROM `table_name`
WHERE EXISTS (SELECT 1 FROM UNNEST(Experience) WHERE Company = 'GE')

How to filter an array of Struct on matching multiple fields in the Struct using Standard Sql?
#standardSQL
WITH data AS (
SELECT
STRUCT<name STRING, start_time INT64, end_time INT64>('jobA', 1, 2) AS job,
[STRUCT<database STRING, schema STRING, table STRING, partition_time INT64>
('d1', 's1', 't1', 1),
('d1', 's2', 't2', 2),
('d1', 's3', 't3', 3)
] AS source UNION ALL
SELECT
STRUCT<name STRING, start_time INT64, end_time INT64>('jobB', 1, 2) AS job,
[STRUCT<database STRING, schema STRING, table STRING, partition_time INT64>
('d1', 's1', 't1', 1),
('d2', 's4', 't2', 2),
('d2', 's3', 't3', 3)
] AS source
)
SELECT *
FROM data
WHERE EXISTS (
SELECT 1 FROM UNNEST(source) AS s
WHERE (s.schema, s.table) = ('s2', 't2')
)

In BigQuery, an array is an ordered list consisting of zero or more values of the same data type. You can construct arrays of simple data types, such as INT64, and complex data types, such as STRUCTs. The current exception to this is the ARRAY data type because arrays of arrays are not supported. To learn more about the ARRAY data type, including NULL handling, see Array type.
With BigQuery, you can construct array literals, build arrays from subqueries using the ARRAY function, and aggregate values into an array using the ARRAY_AGG function.
You can combine arrays using functions like ARRAY_CONCAT(), and convert arrays to strings using ARRAY_TO_STRING().
Using array literals
You can build an array literal in BigQuery using brackets ([ and ]). Each element in an array is separated by a comma.
SELECT [1, 2, 3] as numbers; SELECT ["apple", "pear", "orange"] as fruit; SELECT [true, false, true] as booleans;
You can also create arrays from any expressions that have compatible types. For example:
SELECT [a, b, c]
FROM
(SELECT 5 AS a,
37 AS b,
406 AS c);
SELECT [a, b, c]
FROM
(SELECT CAST(5 AS INT64) AS a,
CAST(37 AS FLOAT64) AS b,
406 AS c);
Notice that the second example contains three expressions: one that returns an INT64, one that returns a FLOAT64, and one that declares a literal. This expression works because all three expressions share FLOAT64 as a supertype.
To declare a specific data type for an array, use angle brackets (< and >). For example:
SELECT ARRAY<FLOAT64>[1, 2, 3] as floats;
Arrays of most data types, such as INT64 or STRING, don’t require that you declare them first.
SELECT [1, 2, 3] as numbers;
You can write an empty array of a specific type using ARRAY<type>[]. You can also write an untyped empty array using [], in which case BigQuery attempts to infer the array type from the surrounding context. If BigQuery cannot infer a type, the default type ARRAY<INT64> is used.
Using generated values
You can also construct an ARRAY with generated values.
GENERATE_ARRAY generates an array of values from a starting and ending value and a step value. For example, the following query generates an array that contains all of the odd integers from 11 to 33, inclusive:
SELECT GENERATE_ARRAY(11, 33, 2) AS odds;
+--------------------------------------------------+ | odds | +--------------------------------------------------+ | [11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33] | +--------------------------------------------------+
You can also generate an array of values in descending order by giving a negative step value:
SELECT GENERATE_ARRAY(21, 14, -1) AS countdown;
+----------------------------------+ | countdown | +----------------------------------+ | [21, 20, 19, 18, 17, 16, 15, 14] | +----------------------------------+
Generating arrays of dates
GENERATE_DATE_ARRAY generates an array of DATEs from a starting and ending DATE and a step INTERVAL.
You can generate a set of DATE values using GENERATE_DATE_ARRAY. For example, this query returns the current DATE and the following DATEs at 1 WEEK intervals up to and including a later DATE:
SELECT
GENERATE_DATE_ARRAY('2017-11-21', '2017-12-21', INTERVAL 1 WEEK)
AS date_array;
+-------------------------------------------------------------+ | date_array | +-------------------------------------------------------------+ | [2017-11-21, 2017-11-28, 2017-12-05, 2017-12-12, 2017-12-19 | +-------------------------------------------------------------+
Consider the following table, sequences:
+---------------------+ | some_numbers | +---------------------+ | [0, 1, 1, 2, 3, 5] | | [2, 4, 8, 16, 32] | | [5, 10] | +---------------------+
This table contains the column some_numbers of the ARRAY data type. To access elements from the arrays in this column, you must specify which type of indexing you want to use: either OFFSET, for zero-based indexes, or ORDINAL, for one-based indexes.
WITH sequences AS
(SELECT [0, 1, 1, 2, 3, 5] AS some_numbers
UNION ALL SELECT [2, 4, 8, 16, 32] AS some_numbers
UNION ALL SELECT [5, 10] AS some_numbers)
SELECT some_numbers,
some_numbers[OFFSET(1)] AS offset_1,
some_numbers[ORDINAL(1)] AS ordinal_1
FROM sequences;
+--------------------+----------+-----------+ | some_numbers | offset_1 | ordinal_1 | +--------------------+----------+-----------+ | [0, 1, 1, 2, 3, 5] | 1 | 0 | | [2, 4, 8, 16, 32] | 4 | 2 | | [5, 10] | 10 | 5 | +--------------------+----------+-----------+
Note:OFFSET() and ORDINAL() will raise errors if the index is out of range. To avoid this, you can use SAFE_OFFSET() or SAFE_ORDINAL() to return NULL instead of raising an error.
WITH sequences AS
(SELECT [0, 1, 1, 2, 3, 5] AS some_numbers
UNION ALL SELECT [2, 4, 8, 16, 32] AS some_numbers
UNION ALL SELECT [5, 10] AS some_numbers)
SELECT some_numbers,
some_numbers[SAFE_OFFSET(2)] AS offset_1,
some_numbers[SAFE_ORDINAL(2)] AS ordinal_1
FROM sequences;
+--------------------+----------+-----------+ | some_numbers | offset_1 | ordinal_1 | +--------------------+----------+-----------+ | [0, 1, 1, 2, 3, 5] | 1 | 1 | | [2, 4, 8, 16, 32] | 8 | 4 | | [5, 10] | NULL | 10 | +--------------------+----------+-----------+
The ARRAY_LENGTH() function returns the length of an array.
WITH sequences AS
(SELECT [0, 1, 1, 2, 3, 5] AS some_numbers
UNION ALL SELECT [2, 4, 8, 16, 32] AS some_numbers
UNION ALL SELECT [5, 10] AS some_numbers)
SELECT some_numbers,
ARRAY_LENGTH(some_numbers) AS len
FROM sequences;
+--------------------+--------+ | some_numbers | len | +--------------------+--------+ | [0, 1, 1, 2, 3, 5] | 6 | | [2, 4, 8, 16, 32] | 5 | | [5, 10] | 2 | +--------------------+--------+
To convert an ARRAY into a set of rows, also known as “flattening,” use the UNNEST operator. UNNEST takes an ARRAY and returns a table with a single row for each element in the ARRAY.
Because UNNEST destroys the order of the ARRAY elements, you may wish to restore order to the table. To do so, use the optional WITH OFFSET clause to return an additional column with the offset for each array element, then use the ORDER BY clause to order the rows by their offset.
SELECT * FROM UNNEST(['foo', 'bar', 'baz', 'qux', 'corge', 'garply', 'waldo', 'fred']) AS element WITH OFFSET AS offset ORDER BY offset;
+----------+--------+ | element | offset | +----------+--------+ | foo | 0 | | bar | 1 | | baz | 2 | | qux | 3 | | corge | 4 | | garply | 5 | | waldo | 6 | | fred | 7 | +----------+--------+
To flatten an entire column of ARRAYs while preserving the values of the other columns in each row, use a correlated cross join to join the table containing the ARRAY column to the UNNEST output of that ARRAY column.
With a correlated join, the UNNEST operator references the ARRAY typed column from each row in the source table, which appears previously in the FROM clause. For each row N in the source table, UNNEST flattens the ARRAY from row N into a set of rows containing the ARRAY elements, and then the cross join joins this new set of rows with the single row N from the source table.
The following example uses UNNEST to return a row for each element in the array column. Because of the CROSS JOIN, the id column contains the id values for the row in sequences that contains each number.
WITH sequences AS (SELECT 1 AS id, [0, 1, 1, 2, 3, 5] AS some_numbers UNION ALL SELECT 2 AS id, [2, 4, 8, 16, 32] AS some_numbers UNION ALL SELECT 3 AS id, [5, 10] AS some_numbers) SELECT id, flattened_numbers FROM sequences CROSS JOIN UNNEST(sequences.some_numbers) AS flattened_numbers;
+------+-------------------+ | id | flattened_numbers | +------+-------------------+ | 1 | 0 | | 1 | 1 | | 1 | 1 | | 1 | 2 | | 1 | 3 | | 1 | 5 | | 2 | 2 | | 2 | 4 | | 2 | 8 | | 2 | 16 | | 2 | 32 | | 3 | 5 | | 3 | 10 | +------+-------------------+
Note that for correlated cross joins the UNNEST operator is optional and the CROSS JOIN can be expressed as a comma-join. Using this shorthand notation, the above example becomes:
WITH sequences AS (SELECT 1 AS id, [0, 1, 1, 2, 3, 5] AS some_numbers UNION ALL SELECT 2 AS id, [2, 4, 8, 16, 32] AS some_numbers UNION ALL SELECT 3 AS id, [5, 10] AS some_numbers) SELECT id, flattened_numbers FROM sequences, sequences.some_numbers AS flattened_numbers;
or
WITH sequences AS (SELECT 1 AS id, [0, 1, 1, 2, 3, 5] AS some_numbers UNION ALL SELECT 2 AS id, [2, 4, 8, 16, 32] AS some_numbers UNION ALL SELECT 3 AS id, [5, 10] AS some_numbers) SELECT id, flattened_numbers FROM sequences, UNNEST(sequences.some_numbers) AS flattened_numbers;
If a table contains an ARRAY of STRUCTs, you can flatten the ARRAY to query the fields of the STRUCT. You can also flatten ARRAY type fields of STRUCT values.
Querying STRUCT elements in an ARRAY
The following example uses UNNEST with CROSS JOIN to flatten an ARRAY of STRUCTs.
WITH races AS (
SELECT "800M" AS race,
[STRUCT("Rudisha" as name, [23.4, 26.3, 26.4, 26.1] as laps),
STRUCT("Makhloufi" as name, [24.5, 25.4, 26.6, 26.1] as laps),
STRUCT("Murphy" as name, [23.9, 26.0, 27.0, 26.0] as laps),
STRUCT("Bosse" as name, [23.6, 26.2, 26.5, 27.1] as laps),
STRUCT("Rotich" as name, [24.7, 25.6, 26.9, 26.4] as laps),
STRUCT("Lewandowski" as name, [25.0, 25.7, 26.3, 27.2] as laps),
STRUCT("Kipketer" as name, [23.2, 26.1, 27.3, 29.4] as laps),
STRUCT("Berian" as name, [23.7, 26.1, 27.0, 29.3] as laps)]
AS participants)
SELECT
race,
participant
FROM races r
CROSS JOIN UNNEST(r.participants) as participant;
+------+---------------------------------------+
| race | participant |
+------+---------------------------------------+
| 800M | {Rudisha, [23.4, 26.3, 26.4, 26.1]} |
| 800M | {Makhloufi, [24.5, 25.4, 26.6, 26.1]} |
| 800M | {Murphy, [23.9, 26, 27, 26]} |
| 800M | {Bosse, [23.6, 26.2, 26.5, 27.1]} |
| 800M | {Rotich, [24.7, 25.6, 26.9, 26.4]} |
| 800M | {Lewandowski, [25, 25.7, 26.3, 27.2]} |
| 800M | {Kipketer, [23.2, 26.1, 27.3, 29.4]} |
| 800M | {Berian, [23.7, 26.1, 27, 29.3]} |
+------+---------------------------------------+
You can find specific information from repeated fields. For example, the following query returns the fastest racer in an 800M race.
WITH races AS (
SELECT "800M" AS race,
[STRUCT("Rudisha" as name, [23.4, 26.3, 26.4, 26.1] as laps),
STRUCT("Makhloufi" as name, [24.5, 25.4, 26.6, 26.1] as laps),
STRUCT("Murphy" as name, [23.9, 26.0, 27.0, 26.0] as laps),
STRUCT("Bosse" as name, [23.6, 26.2, 26.5, 27.1] as laps),
STRUCT("Rotich" as name, [24.7, 25.6, 26.9, 26.4] as laps),
STRUCT("Lewandowski" as name, [25.0, 25.7, 26.3, 27.2] as laps),
STRUCT("Kipketer" as name, [23.2, 26.1, 27.3, 29.4] as laps),
STRUCT("Berian" as name, [23.7, 26.1, 27.0, 29.3] as laps)]
AS participants)
SELECT
race,
(SELECT name
FROM UNNEST(participants)
ORDER BY (
SELECT SUM(duration)
FROM UNNEST(laps) AS duration) ASC
LIMIT 1) AS fastest_racer
FROM races;
+------+---------------+ | race | fastest_racer | +------+---------------+ | 800M | Rudisha | +------+---------------+
Querying ARRAY-type fields in a STRUCT
You can also get information from nested repeated fields. For example, the following statement returns the runner who had the fastest lap in an 800M race.
+------+-------------------------+ | race | runner_with_fastest_lap | +------+-------------------------+ | 800M | Kipketer | +------+-------------------------+
Notice that the preceding query uses the comma operator (,) to perform an implicit CROSS JOIN. It is equivalent to the following example, which uses an explicit CROSS JOIN.
WITH races AS (
SELECT "800M" AS race,
[STRUCT("Rudisha" as name, [23.4, 26.3, 26.4, 26.1] as laps),
STRUCT("Makhloufi" as name, [24.5, 25.4, 26.6, 26.1] as laps),
STRUCT("Murphy" as name, [23.9, 26.0, 27.0, 26.0] as laps),
STRUCT("Bosse" as name, [23.6, 26.2, 26.5, 27.1] as laps),
STRUCT("Rotich" as name, [24.7, 25.6, 26.9, 26.4] as laps),
STRUCT("Lewandowski" as name, [25.0, 25.7, 26.3, 27.2] as laps),
STRUCT("Kipketer" as name, [23.2, 26.1, 27.3, 29.4] as laps),
STRUCT("Berian" as name, [23.7, 26.1, 27.0, 29.3] as laps)]
AS participants)
SELECT
race,
(SELECT name
FROM UNNEST(participants)
CROSS JOIN UNNEST(laps) AS duration
ORDER BY duration ASC LIMIT 1) AS runner_with_fastest_lap
FROM races;
Flattening arrays with a CROSS JOIN excludes rows that have empty or NULL arrays. If you want to include these rows, use a LEFT JOIN.
WITH races AS (
SELECT "800M" AS race,
[STRUCT("Rudisha" as name, [23.4, 26.3, 26.4, 26.1] as laps),
STRUCT("Makhloufi" as name, [24.5, 25.4, 26.6, 26.1] as laps),
STRUCT("Murphy" as name, [23.9, 26.0, 27.0, 26.0] as laps),
STRUCT("Bosse" as name, [23.6, 26.2, 26.5, 27.1] as laps),
STRUCT("Rotich" as name, [24.7, 25.6, 26.9, 26.4] as laps),
STRUCT("Lewandowski" as name, [25.0, 25.7, 26.3, 27.2] as laps),
STRUCT("Kipketer" as name, [23.2, 26.1, 27.3, 29.4] as laps),
STRUCT("Berian" as name, [23.7, 26.1, 27.0, 29.3] as laps),
STRUCT("Nathan" as name, ARRAY<FLOAT64>[] as laps),
STRUCT("David" as name, NULL as laps)]
AS participants)
SELECT
name, sum(duration) AS finish_time
FROM races, races.participants
LEFT JOIN participants.laps duration
GROUP BY name;
+-------------+--------------------+ | name | finish_time | +-------------+--------------------+ | Murphy | 102.9 | | Rudisha | 102.19999999999999 | | David | NULL | | Rotich | 103.6 | | Makhloufi | 102.6 | | Berian | 106.1 | | Bosse | 103.4 | | Kipketer | 106 | | Nathan | NULL | | Lewandowski | 104.2 | +-------------+--------------------+
A common task when working with arrays is turning a subquery result into an array. In BigQuery, you can accomplish this using the ARRAY() function.
For example, consider the following operation on the sequences table:
WITH sequences AS
(SELECT [0, 1, 1, 2, 3, 5] AS some_numbers
UNION ALL SELECT [2, 4, 8, 16, 32] AS some_numbers
UNION ALL SELECT [5, 10] AS some_numbers)
SELECT some_numbers,
ARRAY(SELECT x * 2
FROM UNNEST(some_numbers) AS x) AS doubled
FROM sequences;
+--------------------+---------------------+ | some_numbers | doubled | +--------------------+---------------------+ | [0, 1, 1, 2, 3, 5] | [0, 2, 2, 4, 6, 10] | | [2, 4, 8, 16, 32] | [4, 8, 16, 32, 64] | | [5, 10] | [10, 20] | +--------------------+---------------------+
This example starts with a table named sequences. This table contains a column, some_numbers, of type ARRAY<INT64>.
The query itself contains a subquery. This subquery selects each row in the some_numbers column and uses UNNEST to return the array as a set of rows. Next, it multiplies each value by two, and then recombines the rows back into an array using the ARRAY() operator.
The following example uses a WHERE clause in the ARRAY() operator’s subquery to filter the returned rows.
Note: In the following examples, the resulting rows are not ordered.
WITH sequences AS
(SELECT [0, 1, 1, 2, 3, 5] AS some_numbers
UNION ALL SELECT [2, 4, 8, 16, 32] AS some_numbers
UNION ALL SELECT [5, 10] AS some_numbers)
SELECT
ARRAY(SELECT x * 2
FROM UNNEST(some_numbers) AS x
WHERE x < 5) AS doubled_less_than_five
FROM sequences;
+------------------------+ | doubled_less_than_five | +------------------------+ | [0, 2, 2, 4, 6] | | [4, 8] | | [] | +------------------------+
Notice that the third row contains an empty array, because the elements in the corresponding original row ([5, 10]) did not meet the filter requirement of x < 5.
You can also filter arrays by using SELECT DISTINCT to return only unique elements within an array.
WITH sequences AS
(SELECT [0, 1, 1, 2, 3, 5] AS some_numbers)
SELECT ARRAY(SELECT DISTINCT x
FROM UNNEST(some_numbers) AS x) AS unique_numbers
FROM sequences;
+-----------------+ | unique_numbers | +-----------------+ | [0, 1, 2, 3, 5] | +-----------------+
WITH sequences AS
(SELECT [0, 1, 1, 2, 3, 5] AS some_numbers
UNION ALL SELECT [2, 4, 8, 16, 32] AS some_numbers
UNION ALL SELECT [5, 10] AS some_numbers)
SELECT
ARRAY(SELECT x
FROM UNNEST(some_numbers) AS x
WHERE 2 IN UNNEST(some_numbers)) AS contains_two
FROM sequences;
+--------------------+ | contains_two | +--------------------+ | [0, 1, 1, 2, 3, 5] | | [2, 4, 8, 16, 32] | | [] | +--------------------+
Notice again that the third row contains an empty array, because the array in the corresponding original row ([5, 10]) did not contain 2.
To check if an array contains a specific value, use the IN operator with UNNEST. To check if an array contains a value matching a condition, use the EXISTS operator with UNNEST.
Scanning for specific values
To scan an array for a specific value, use the IN operator with UNNEST.
The following example returns true if the array contains the number 2.
SELECT 2 IN UNNEST([0, 1, 1, 2, 3, 5]) AS contains_value;
+----------------+ | contains_value | +----------------+ | true | +----------------+
To return the rows of a table where the array column contains a specific value, filter the results of IN UNNEST using the WHERE clause.
The following example returns the id value for the rows where the array column contains the value 2.
WITH sequences AS (SELECT 1 AS id, [0, 1, 1, 2, 3, 5] AS some_numbers UNION ALL SELECT 2 AS id, [2, 4, 8, 16, 32] AS some_numbers UNION ALL SELECT 3 AS id, [5, 10] AS some_numbers) SELECT id AS matching_rows FROM sequences WHERE 2 IN UNNEST(sequences.some_numbers) ORDER BY matching_rows;
+---------------+ | matching_rows | +---------------+ | 1 | | 2 | +---------------+
Scanning for values that satisfy a condition
To scan an array for values that match a condition, use UNNEST to return a table of the elements in the array, use WHERE to filter the resulting table in a subquery, and use EXISTS to check if the filtered table contains any rows.
The following example returns the id value for the rows where the array column contains values greater than 5.
WITH
Sequences AS (
SELECT 1 AS id, [0, 1, 1, 2, 3, 5] AS some_numbers
UNION ALL
SELECT 2 AS id, [2, 4, 8, 16, 32] AS some_numbers
UNION ALL
SELECT 3 AS id, [5, 10] AS some_numbers
)
SELECT id AS matching_rows
FROM Sequences
WHERE EXISTS(SELECT * FROM UNNEST(some_numbers) AS x WHERE x > 5);
+---------------+ | matching_rows | +---------------+ | 2 | | 3 | +---------------+
Scanning for STRUCT field values that satisfy a condition
To search an array of STRUCTs for a field whose value matches a condition, use UNNEST to return a table with a column for each STRUCT field, then filter non-matching rows from the table using WHERE EXISTS.
The following example returns the rows where the array column contains a STRUCT whose field b has a value greater than 3.
WITH
Sequences AS (
SELECT 1 AS id, [STRUCT(0 AS a, 1 AS b)] AS some_numbers
UNION ALL
SELECT 2 AS id, [STRUCT(2 AS a, 4 AS b)] AS some_numbers
UNION ALL
SELECT 3 AS id, [STRUCT(5 AS a, 3 AS b), STRUCT(7 AS a, 4 AS b)] AS some_numbers
)
SELECT id AS matching_rows
FROM Sequences
WHERE EXISTS(SELECT 1 FROM UNNEST(some_numbers) WHERE b > 3);
+---------------+ | matching_rows | +---------------+ | 2 | | 3 | +---------------+
You can create an empty table with a JSON column by using SQL or by using the bq command-line tool.
CREATE TABLE mydataset.table1( id INT64, cart JSON );
You can create JSON values in the following ways:
JSON literal.PARSE_JSON function to convert a string to a JSON type.TO_JSON function to convert a SQL type to a JSON type.Create a JSON literal
The following example uses a DML statement to insert a JSON literal into a table:
INSERT INTO mydataset.table1
VALUES(1, JSON '{"name": "Alice", "age": 30}');
SELECT * FROM mydataset.table1
+----+---------------------------+
| id | cart |
+----+---------------------------+
| 1 | {"age":30,"name":"Alice"} |
+----+---------------------------+
Convert a string to JSON
The following example converts JSON data stored as a string to a JSON type, by using the PARSE_JSON function. The example converts a column from an existing table to a JSON type and stores the results to a new table.
Convert a SQL type to JSON
The following example converts a SQL STRUCT value to a JSON type, by using the TO_JSON function:
SELECT TO_JSON(STRUCT(1 AS id, [10,20] AS coordinates)) AS pt;
The result is the following:
+--------------------------------+
| pt |
+--------------------------------+
| {"coordinates":[10,20],"id":1} |
+--------------------------------+
You can ingest JSON data into a BigQuery table in the following ways:
tabledata.insertAll streaming API.This section describes how to use Standard SQL to extract values from the JSON. JSON is case-sensitive and supports UTF-8 in both fields and values.
The examples in this section use the following table:
CREATE OR REPLACE TABLE mydataset.table1(id INT64, cart JSON);
INSERT INTO mydataset.table1 VALUES
(1, JSON """{
"name": "Alice",
"items": [
{"product": "book", "price": 10},
{"product": "food", "price": 5}
]
}"""),
(2, JSON """{
"name": "Bob",
"items": [
{"product": "pen", "price": 20}
]
}""");
Extract values as JSON
Given a JSON type in BigQuery, you can access the fields in a JSON expression by using the field access operator. The following example returns the name field of the cart column.
SELECT cart.name FROM mydataset.table1;
+---------+ | name | +---------+ | "Alice" | | "Bob" | +---------+
To access an array element, use the JSON subscript operator. The following example returns the first element of the items array:
SELECT cart.items[0] AS first_item FROM mydataset.table1
+-------------------------------+
| first_item |
+-------------------------------+
| {"price":10,"product":"book"} |
| {"price":20,"product":"pen"} |
+-------------------------------+
SELECT cart.items[1] AS first_item FROM mydataset.table1
+-------------------------------+
| first_item |
+-------------------------------+
| {"price":5,"product":"food"} |
| NULL |
+-------------------------------+
You can also use the JSON subscript operator to reference the members of a JSON object by name:
SELECT cart['name'] FROM mydataset.table1;
+---------+ | name | +---------+ | "Alice" | | "Bob" | +---------+
For subscript operations, the expression inside the brackets can be any arbitrary string or integer expression, including non-constant expressions:
DECLARE int_val INT64 DEFAULT 0;
SELECT
cart[CONCAT('it','ems')][int_val + 1].product AS item
FROM mydataset.table1;
+--------+ | item | +--------+ | "food" | | NULL | +--------+
Field access and subscript operators both return JSON types, so you can chain expressions that use them or pass the result to other functions that take JSON types.
These operators are syntactic sugar for the JSON_QUERY function. For example, the expression cart.name is equivalent to JSON_QUERY(cart, "$.name").
If a member with the specified name is not found in the JSON object, or if the JSON array doesn’t have an element with the specified position, then these operators return SQL NULL.
SELECT cart.address AS address, cart.items[1].price AS item1_price FROM mydataset.table1;
+---------+-------------+ | address | item1_price | +---------+-------------+ | NULL | 5 | | NULL | NULL | +---------+-------------+
The equality and comparison operators are not defined on the JSON data type. Therefore, you can’t use JSON values directly in clauses like GROUP BY or ORDER BY. Instead, use the JSON_VALUE function to extract field values as SQL strings, as described in the next section.
Extract values as strings
The JSON_VALUE function extracts a scalar value and returns it as a SQL string. It returns SQL NULL if cart.name doesn’t point to a scalar value in the JSON.
SELECT JSON_VALUE(cart.name) AS name FROM mydataset.table1;
+-------+ | name | +-------+ | Alice | +-------+
You can use the JSON_VALUE function in contexts that require equality or comparison, such as WHERE clauses and GROUP BY clauses. The following example shows a WHERE clause that filters against a JSON value:
SELECT cart.items[0] AS first_item FROM mydataset.table1 WHERE JSON_VALUE(cart.name) = 'Alice';
+-------------------------------+
| first_item |
+-------------------------------+
| {"price":10,"product":"book"} |
+-------------------------------+
ลอง WHERE โดยไม่ใช้ JSON_VALUE จะได้ error
SELECT cart.items[0] AS first_item FROM mydataset.table1 WHERE cart.name = 'Alice';
No matching signature for operator = for argument types: JSON, STRING. Supported signature: ANY = ANY at [6:3]
Alternatively, you can use the STRING function which extracts a JSON string and returns that value as a SQL STRING. For example:
SELECT STRING(JSON '"purple"') AS color;
+--------+ | color | +--------+ | purple | +--------+
SELECT STRING(JSON_QUERY(JSON '{"name": "sky", "color": "blue"}', "$.color")) AS color;
+--------+ | color | +--------+ | blue | +--------+
In addition to STRING, you might have to extract JSON values and return them as another SQL data type. The following value extraction functions are available:
To obtain the type of the JSON value, you can use the JSON_TYPE function.
Extract arrays from JSON
JSON can contain JSON arrays, which are not directly equivalent to an ARRAY<JSON> type in BigQuery. You can use the following functions to extract a BigQuery ARRAY from JSON:
JSON_QUERY_ARRAY: extracts an array and returns it as an ARRAY<JSON> of JSON.JSON_VALUE_ARRAY: extracts an array of scalar values and returns it as an ARRAY<STRING> of scalar values.The following example uses JSON_QUERY_ARRAY to extract JSON arrays.
SELECT JSON_QUERY_ARRAY(cart.items) AS items FROM mydataset.table1;
+----------------------------------------------------------------+
| items |
+----------------------------------------------------------------+
| [{"price":10,"product":"book"}","{"price":5,"product":"food"}] |
| [{"price":20,"product":"pen"}] |
+----------------------------------------------------------------+
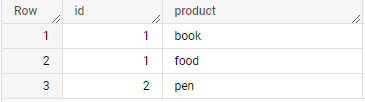
To split an array into its individual elements, use the UNNEST operator, which returns a table with one row for each element in the array. The following example selects the product member from each member of the items array:
SELECT id, JSON_VALUE(item.product) AS product FROM mydataset.table1, UNNEST(JSON_QUERY_ARRAY(cart.items)) AS item ORDER BY id;
+----+---------+ | id | product | +----+---------+ | 1 | book | | 1 | food | | 2 | pen | +----+---------+
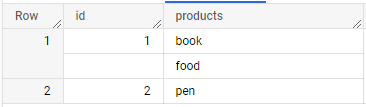
The next example is similar but uses the ARRAY_AGG function to aggregate the values back into a SQL array.
SELECT id, ARRAY_AGG(JSON_VALUE(item.product)) AS products FROM mydataset.table1, UNNEST(JSON_QUERY_ARRAY(cart.items)) AS item GROUP BY id ORDER BY id;
+----+-----------------+ | id | products | +----+-----------------+ | 1 | ["book","food"] | | 2 | ["pen"] | +----+-----------------+
The JSON type has a special null value that is different from the SQL NULL. A JSON null is not treated as a SQL NULL value, as the following example shows.
SELECT JSON 'null' IS NULL;
+-------+ | f0_ | +-------+ | false | +-------+
When you extract a JSON field with a null value, the behavior depends on the function:
JSON_QUERY function returns a JSON null, because it is a valid JSON value.JSON_VALUE function returns the SQL NULL, because JSON null is not a scalar value.The following example shows the different behaviors:
SELECT
json.a AS json_query, -- Equivalent to JSON_QUERY(json, '$.a')
JSON_VALUE(json, '$.a') AS json_value
FROM (SELECT JSON '{"a": null}' AS json);
+------------+------------+ | json_query | json_value | +------------+------------+ | null | NULL | +------------+------------+