
- Example1
- Command-Line Interface
- Example2
Category Archives: Python3
Visualize tree in bash like unix tree command
- python – Visualize tree in bash, like the output of unix “tree” – Stack Overflow
- Build a Python Directory Tree Generator for the Command Line – Real Python
# tree.py
import six
branch = '├'
pipe = '|'
end = '└'
dash = '─'
class Tree(object):
def __init__(self, tag):
self.tag = tag
class Node(Tree):
def __init__(self, tag, *nodes):
super(Node, self).__init__(tag)
self.nodes = list(nodes)
class Leaf(Tree):
pass
def _draw_tree(tree, level, last=False, sup=[]):
def update(left, i):
if i < len(left):
left[i] = ' '
return left
print(''.join(six.moves.reduce(update, sup, ['{} '.format(pipe)] * level)) \
+ (end if last else branch) + '{} '.format(dash) \
+ str(tree.tag))
if isinstance(tree, Node):
level += 1
for node in tree.nodes[:-1]:
_draw_tree(node, level, sup=sup)
_draw_tree(tree.nodes[-1], level, True, [level] + sup)
def draw_tree(trees):
for tree in trees[:-1]:
_draw_tree(tree, 0)
_draw_tree(trees[-1], 0, True, [0])
class Track(object):
def __init__(self, parent, idx):
self.parent, self.idx = parent, idx
def parser(text):
trees = []
tracks = {}
for line in text.splitlines():
line = line.strip()
key, value = map(lambda s: s.strip(), line.split(':', 1))
nodes = value.split()
if len(nodes):
parent = Node(key)
for i, node in enumerate(nodes):
tracks[node] = Track(parent, i)
parent.nodes.append(Leaf(node))
curnode = parent
if curnode.tag in tracks:
t = tracks[curnode.tag]
t.parent.nodes[t.idx] = curnode
else:
trees.append(curnode)
else:
curnode = Leaf(key)
if curnode.tag in tracks:
# well, how you want to handle it?
pass # ignore
else:
trees.append(curnode)
return trees
if __name__ == '__main__':
text='''apple: banana eggplant
banana: cantaloupe durian
eggplant:
fig:'''
draw_tree(parser(text))
print()
text='''apple: banana eggplant
banana: cantaloupe durian
eggplant:'''
draw_tree(parser(text))
print()
text='''apple: banana
banana: cantaloupe durian
eggplant:'''
draw_tree(parser(text))
> python .\tree.py ├─ apple | ├─ banana | | ├─ cantaloupe | | └─ durian | └─ eggplant └─ fig └─ apple ├─ banana | ├─ cantaloupe | └─ durian └─ eggplant ├─ apple | └─ banana | ├─ cantaloupe | └─ durian └─ eggplant
flask-session
การอัพโหลดไฟล์ จำเป็นต้องมีการกำหนดค่า SECRET_KEY ไม่งั้นจะ error ว่า RuntimeError: The session is unavailable because no secret key was set. Set the secret_key on the application to something unique and secret.
# save this as app.py
from flask import Flask
from flask import session
import os
app = Flask(__name__)
app.config.update(SECRET_KEY=os.urandom(24))
app.config.from_object(__name__)
@app.route("/")
def hello():
return "Hello, World!"
if __name__ == "__main__":
with app.test_request_context("/"):
session["key"] = "value"
Flask-Markdown
- ติดตั้ง Flask
- ทดลองใช้ Markdown
- แสดง code ด้วย Markdown
Flask
- Flask · PyPI
- Primer on Jinja Templating – Real Python
- Welcome to Flask — Flask Documentation (2.3.x) (palletsprojects.com)
- Tutorial — Flask Documentation (2.3.x) (palletsprojects.com)
Installing
$ pip install -U Flask
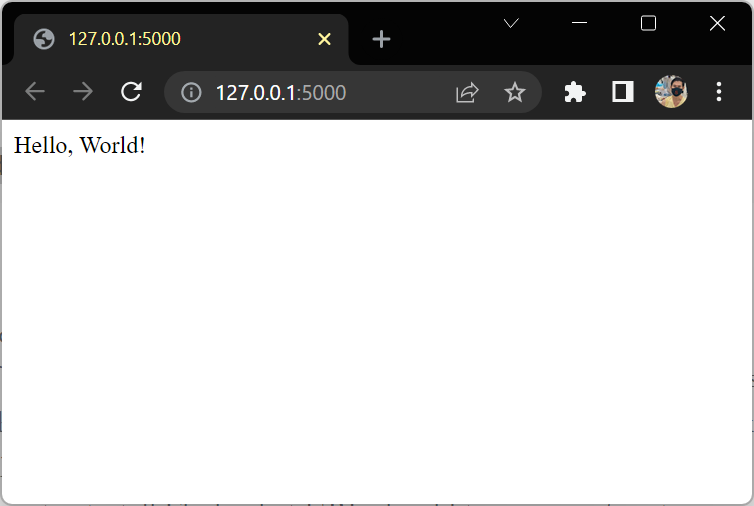
A Simple Example
# save this as app.py
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "Hello, World!"
or
# app.py
from flask import Flask
app = Flask(__name__)
@app.route("/")
def home():
return "Hello, World!"
if __name__ == "__main__":
app.run(debug=True)
$ flask run * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
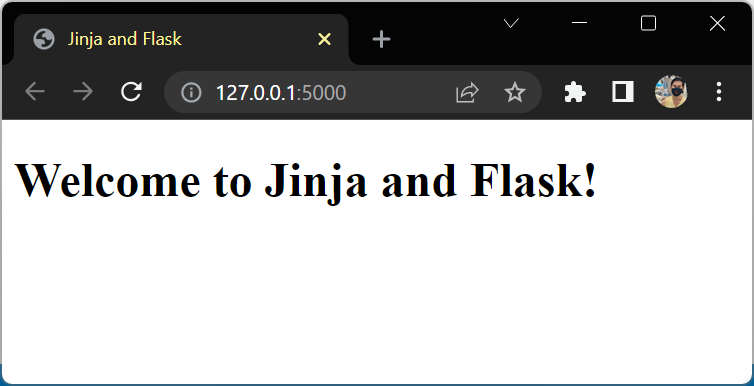
Add a Base Template
{# templates/base.html #}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>{{ title }}</title>
</head>
<body>
<h1>Welcome to {{ title }}!</h1>
</body>
</html>
# app.py
from flask import Flask
from flask import render_template
app = Flask(__name__)
@app.route("/")
def home():
return render_template("base.html", title="Jinja and Flask")
if __name__ == "__main__":
app.run(debug=True)
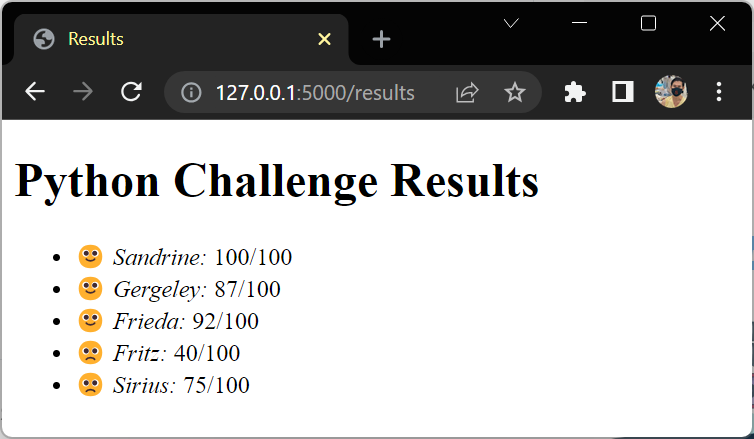
Add Another Page
{# templates/results.html #}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>{{ title }}</title>
</head>
<body>
<h1>{{ test_name }} {{ title }}</h1>
<ul>
{% for student in students %}
<li>
{% if student.score > 80 %}🙂{% else %}🙁{% endif %}
<em>{{ student.name }}:</em> {{ student.score }}/{{ max_score }}
</li>
{% endfor %}
</ul>
</body>
</html>
# app.py
from flask import Flask
from flask import render_template
app = Flask(__name__)
@app.route("/")
def home():
return render_template("base.html", title="Jinja and Flask")
max_score = 100
test_name = "Python Challenge"
students = [
{"name": "Sandrine", "score": 100},
{"name": "Gergeley", "score": 87},
{"name": "Frieda", "score": 92},
{"name": "Fritz", "score": 40},
{"name": "Sirius", "score": 75},
]
@app.route("/results")
def results():
context = {
"title": "Results",
"students": students,
"test_name": test_name,
"max_score": max_score,
}
return render_template("results.html", **context)
if __name__ == "__main__":
app.run(debug=True)
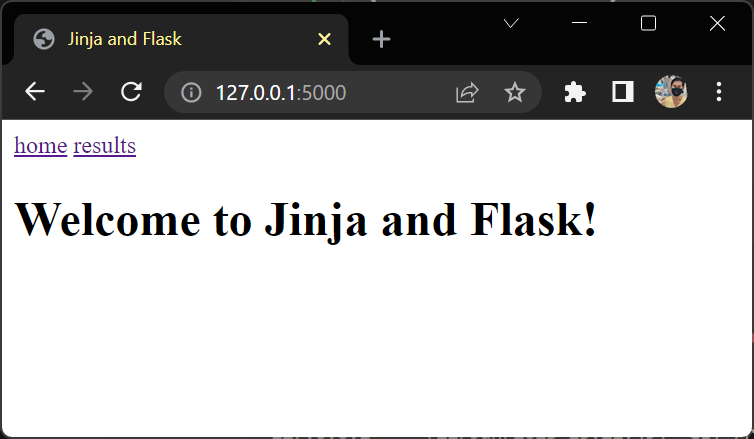
Nest Your Templates
Adjust Your Base Template
{# templates/base.html #}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>{% block title %}{{ title }}{% endblock title %}</title>
</head>
<body>
{% block content %}
<h1>Welcome to {{ title }}!</h1>
{% endblock content %}
</body>
</html>
Extend Child Templates
{# templates/results.html #}
{% extends "base.html" %}
{% block content %}
<h1>{{ test_name }} {{ title }}</h1>
<ul>
{% for student in students %}
<li>
{% if student.score > 80 %}🙂{% else %}🙁{% endif %}
<em>{{ student.name }}:</em> {{ student.score }}/{{ max_score }}
</li>
{% endfor %}
</ul>
{% endblock content %}
Include a Navigation Menu
{# templates/_navigation.html #}
<nav>
{% for menu_item in ["home", "results"] %}
<a href="{{ url_for(menu_item) }}">{{ menu_item }}</a>
{% endfor %}
</nav>
{# templates/base.html #}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>{% block title %}{{ title }}{% endblock title %}</title>
</head>
<body>
<header>
{% include "_navigation.html" %}
</header>
{% block content %}
<h1>Welcome to {{ title }}!</h1>
{% endblock content %}
</body>
</html>
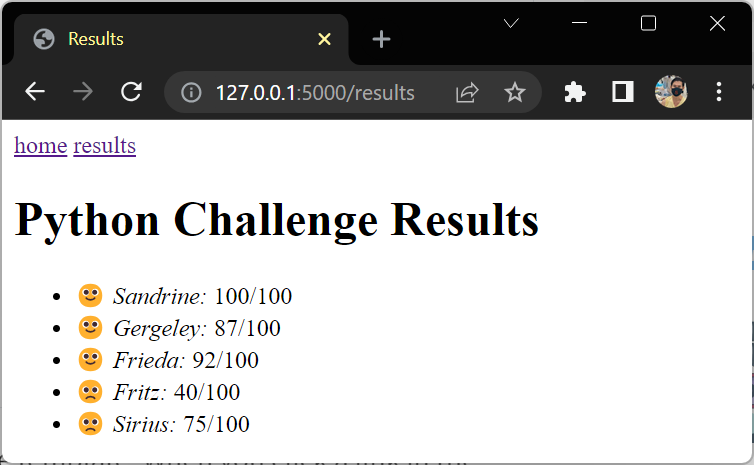
Apply Filters
Adjust Your Menu Items
แสดง link เป็น ตัวพิมพ์ใหญ่ด้วย filter upper
{# templates/_navigation.html #}
<nav>
{% for menu_item in ["home", "results"] %}
<a href="{{ url_for(menu_item) }}">{{ menu_item|upper }}</a>
{% endfor %}
</nav>
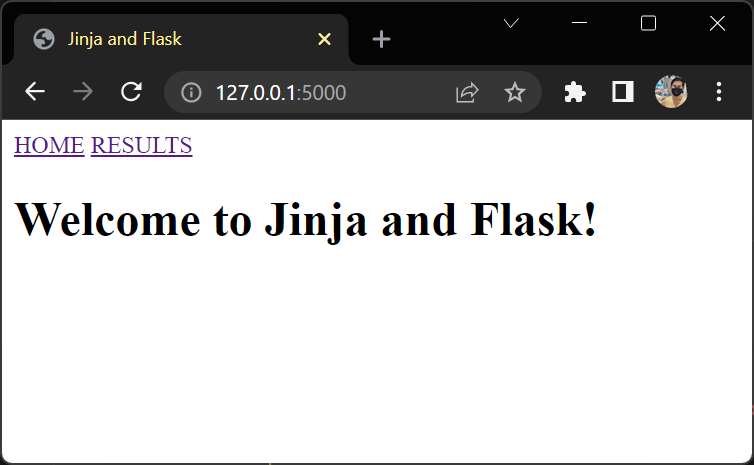
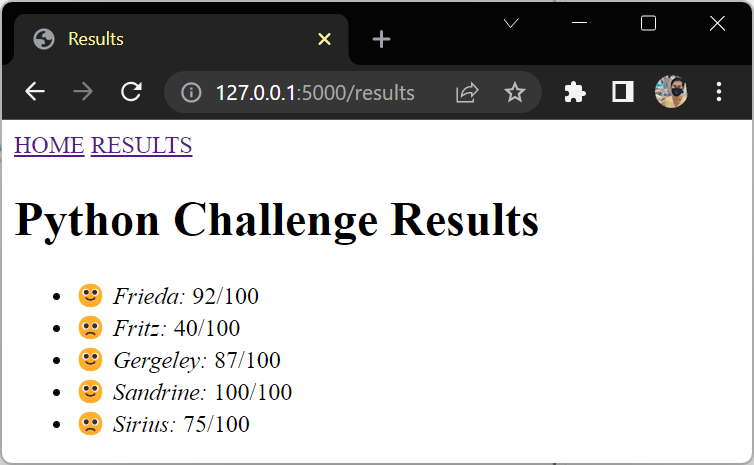
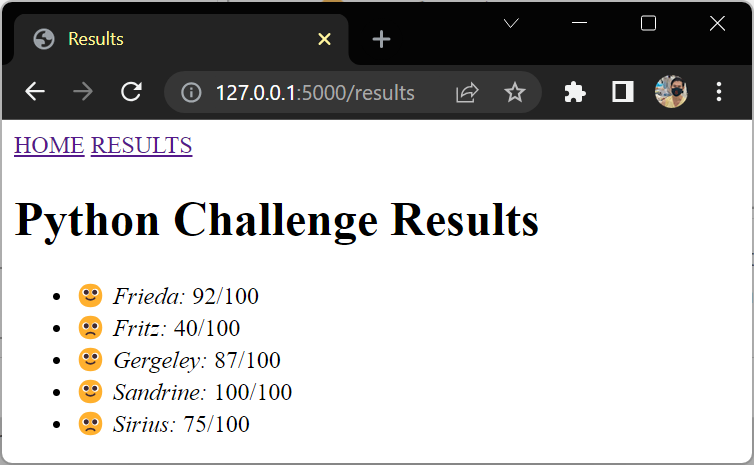
Sort Your Results List
เรียกตาม name ด้วย filter sort
{# templates/results.html #}
{% extends "base.html" %}
{% block content %}
<h1>{{ test_name }} {{ title }}</h1>
<ul>
{% for student in students|sort(attribute="name") %}
<li>
{% if student.score > 80 %}🙂{% else %}🙁{% endif %}
<em>{{ student.name }}:</em> {{ student.score }}/{{ max_score }}
</li>
{% endfor %}
</ul>
{% endblock content %}
You used Jinja’s sort filter to sort the results of your students by their names. If you had students with the same name, then you could chain the filters:
{% for student in students|sort(attribute="score", reverse=true)
|sort(attribute="name") %}
{# ... #}
{% endfor %}
Include Macros
Implement a Dark Mode
{# templates/macros.html #}
{% macro light_or_dark_mode(element) %}
{% if request.args.get('mode') == "dark" %}
<a href="{{ request.path }}">Switch to Light Mode</a>
<style>
{{ element }} {
background-color: #212F3C;
color: #FFFFF0;
}
{{ element }} a {
color: #00BFFF !important;
}
</style>
{% else %}
<a href="{{ request.path }}?mode=dark">Switch to Dark Mode</a>
{% endif %}
{% endmacro %}
{# templates/base.html #}
{% import "macros.html" as macros %}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>{% block title %}{{ title }}{% endblock title %}</title>
</head>
<body>
<header>
{% include "_navigation.html" %}
</header>
{% block content %}
<h1>Welcome to {{ title }}!</h1>
{% endblock content %}
<footer>
{{ macros.light_or_dark_mode("body") }}
</footer>
</body>
</html>
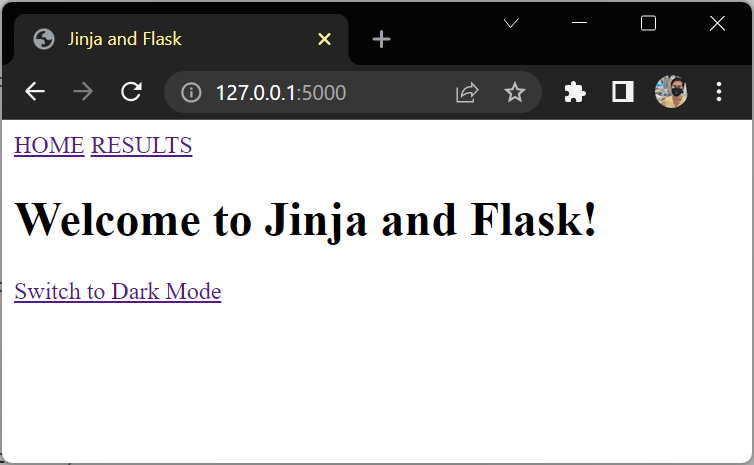
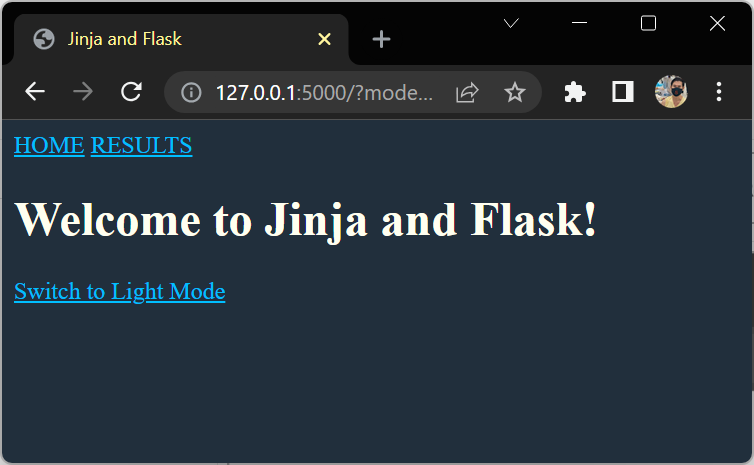
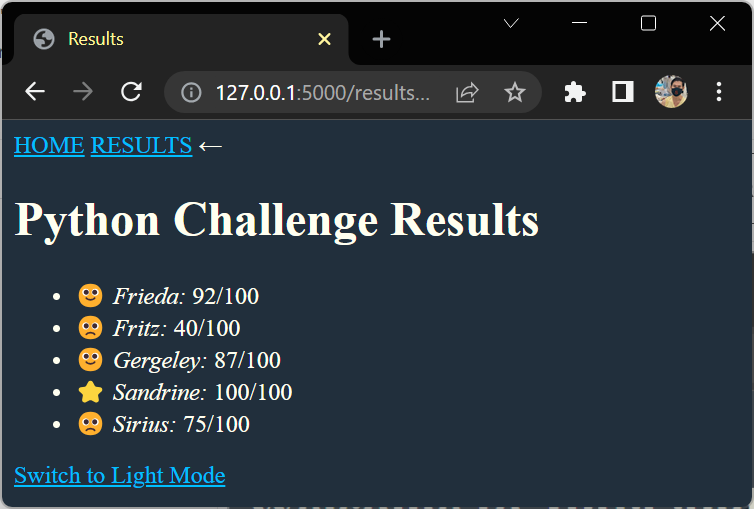
Highlight Your Best Student
{# templates/results.html #}
{% extends "base.html" %}
{% block content %}
<h1>{{ test_name }} {{ title }}</h1>
<ul>
{% for student in students|sort(attribute="name") %}
<li>
{{ macros.add_badge(student, students) }}
<em>{{ student.name }}:</em> {{ student.score }}/{{ max_score }}
</li>
{% endfor %}
</ul>
{% endblock content %}
{# templates/macros.html #}
{% macro light_or_dark_mode(element) %}
{% if request.args.get('mode') == "dark" %}
<a href="{{ request.path }}">Switch to Light Mode</a>
<style>
{{ element }} {
background-color: #212F3C;
color: #FFFFF0;
}
{{ element }} a {
color: #00BFFF !important;
}
</style>
{% else %}
<a href="{{ request.path }}?mode=dark">Switch to Dark Mode</a>
{% endif %}
{% endmacro %}
{% macro add_badge(student, students) %}
{% set high_score = students|map(attribute="score")|max %}
{% if student.score == high_score %}
⭐️
{% elif student.score > 80 %}
🙂
{% else %}
🙁
{% endif %}
{% endmacro %}
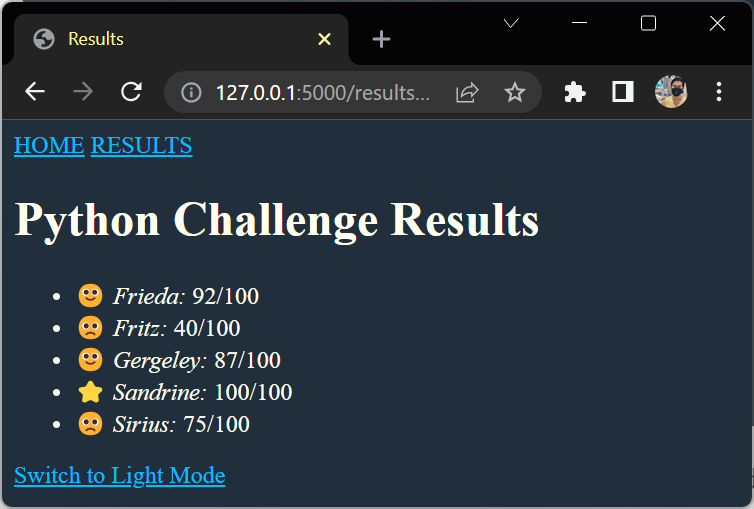
Mark the Current Page
{# templates/macros.html #}
{# ... #}
{% macro nav_link(menu_item) %}
{% set mode = "?mode=dark" if request.args.get("mode") == "dark" else "" %}
<a href="{{ url_for(menu_item) }}{{ mode }}">{{ menu_item|upper }}</a>
{% if request.endpoint == menu_item %}
←
{% endif %}
{% endmacro %}
{# templates/_navigation.html #}
<nav>
{% for menu_item in ["home", "results"] %}
{{ macros.nav_link(menu_item) }}
{% endfor %}
</nav>
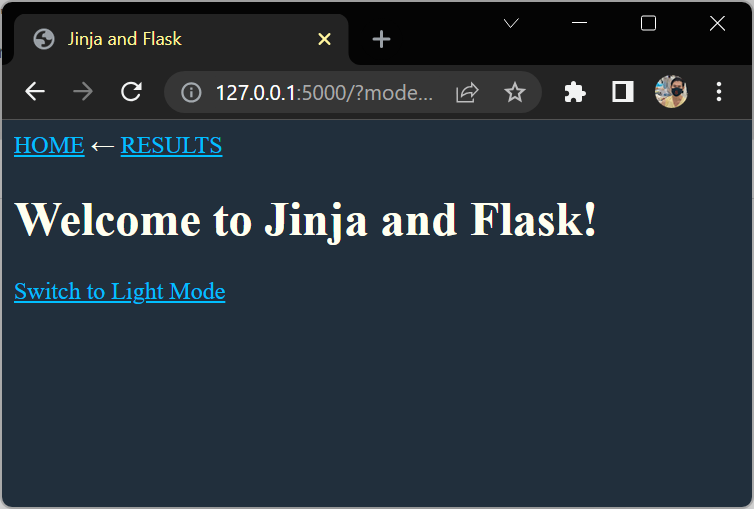
Jinja
- Jinja2 · PyPI
- Primer on Jinja Templating – Real Python
- https://jinja.palletsprojects.com/
- https://github.com/pallets/jinja/
Installing
Set up a virtual environment
> python -m venv venv > .\venv\Scripts\activate (venv) >
ติดตั้ง Jinja2 (จะได้ MarkupSafe มาด้วย)
$ pip install -U Jinja2
> pip list Package Version ---------- ------- Jinja2 3.1.2 MarkupSafe 2.1.3 pip 23.0.1 setuptools 65.5.
Example 1
import jinja2
environment = jinja2.Environment()
template = environment.from_string("Hello, {{ name }}!")
st = template.render(name="World")
print(type(st))
print(st)
# <class 'str'>
# Hello, World!
Example 2 – Use an External File as a Template
{# templates/message.txt #}
Hello {{ name }}!
I'm happy to inform you that you did very well on today's {{ test_name }}.
You reached {{ score }} out of {{ max_score }} points.
See you tomorrow!
Anke
# write_messages.py
from jinja2 import Environment, FileSystemLoader
max_score = 100
test_name = "Python Challenge"
students = [
{"name": "Sandrine", "score": 100},
{"name": "Gergeley", "score": 87},
{"name": "Frieda", "score": 92},
]
environment = Environment(loader=FileSystemLoader("templates/"))
template = environment.get_template("message.txt")
for student in students:
filename = f"message_{student['name'].lower()}.txt"
content = template.render(
student,
max_score=max_score,
test_name=test_name
)
with open(filename, mode="w", encoding="utf-8") as message:
message.write(content)
print(f"... wrote {filename}")
# ... wrote message_sandrine.txt
# ... wrote message_gergeley.txt
# ... wrote message_frieda.txt
รันเสร็จจะได้ไฟล์มา 3 ไฟล์
Example 3 – if
{# templates/message.txt #}
Hello {{ name }}!
{% if score > 80 %}
I'm happy to inform you that you did very well on today's {{ test_name }}.
{% else %}
I'm sorry to inform you that you did not do so well on today's {{ test_name }}.
{% endif %}
You reached {{ score }} out of {{ max_score }} points.
See you tomorrow!
Anke
# write_messages.py
# ...
students = [
{"name": "Sandrine", "score": 100},
{"name": "Gergeley", "score": 87},
{"name": "Frieda", "score": 92},
{"name": "Fritz", "score": 40},
{"name": "Sirius", "score": 75},
]
# ...
Example 4 – Loops
{# templates/results.html #}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Results</title>
</head>
<body>
<h1>{{ test_name }} Results</h1>
<ul>
{% for student in students %}
<li>
{% if student.score > 80 %}🙂{% else %}🙁{% endif %}
<em>{{ student.name }}:</em> {{ student.score }}/{{ max_score }}
</li>
{% endfor %}
</ul>
</body>
</html>
# write_messages.py
# ...
results_filename = "students_results.html"
results_template = environment.get_template("results.html")
context = {
"students": students,
"test_name": test_name,
"max_score": max_score,
}
with open(results_filename, mode="w", encoding="utf-8") as results:
results.write(results_template.render(context))
print(f"... wrote {results_filename}")
MarkupSafe
- https://pypi.org/project/MarkupSafe/
- https://palletsprojects.com/p/markupsafe/
- https://markupsafe.palletsprojects.com/
MarkupSafe implements a text object that escapes characters so it is safe to use in HTML and XML. Characters that have special meanings are replaced so that they display as the actual characters. This mitigates injection attacks, meaning untrusted user input can safely be displayed on a page. Escaping is implemented in C so it is as efficient as possible.
Installing
pip install -U MarkupSafe
Example 1
>>> from markupsafe import Markup, escape
>>> # escape replaces special characters and wraps in Markup
>>> escape("<script>alert(document.cookie);</script>")
Markup('<script>alert(document.cookie);</script>')
>>> escape("<strong>Hello</strong>")
Markup('<strong>Hello</strong>')
>>> # wrap in Markup to mark text "safe" and prevent escaping
>>> Markup("<strong>Hello</strong>")
Markup('<strong>hello</strong>')
>>> escape(Markup("<strong>Hello</strong>"))
Markup('<strong>hello</strong>')
>>> # Markup is a str subclass
>>> # methods and operators escape their arguments
>>> template = Markup("Hello <em>{name}</em>")
>>> template.format(name='"World"')
Markup('Hello <em>"World"</em>')
Example 2
>>> from markupsafe import escape
>>> hello = escape("<em>Hello</em>")
>>> hello
Markup('<em>Hello</em>')
>>> type(hello)
<class 'markupsafe.Markup'>
>>> print(hello)
<em>Hello</em>
>>> escape(hello)
Markup('<em>Hello</em>')
>>> hello + " <strong>World</strong>"
Markup('<em>Hello</em> <strong>World</strong>')
Example 3
A string that is ready to be safely inserted into an HTML or XML document, either because it was escaped or because it was marked safe.
>>> from markupsafe import Markup
>>> Markup("Hello, <em>World</em>!")
Markup('Hello, <em>World</em>!')
>>> Markup(42)
Markup('42')
>>> Markup.escape("Hello, <em>World</em>!")
Markup('Hello, <em>World</em>!')
Example 4
This implements the __html__() interface that some frameworks use. Passing an object that implements __html__() will wrap the output of that method, marking it safe.
>>> from markupsafe import Markup
>>> class Foo:
... def __html__(self):
... return '<a href="/foo">foo</a>'
...
>>> Markup(Foo())
Markup('<a href="/foo">foo</a>')
Example 5 – HTML Representations
from markupsafe import Markup
class Image:
def __init__(self, url):
self.url = url
def __html__(self):
return f'<img src="{self.url}">'
>>> img = Image("/static/logo.png")
>>> Markup(img)
Markup('<img src="/static/logo.png">')
from markupsafe import Markup, escape
class User:
def __init__(self, id, name):
self.id = id
self.name = name
def __html__(self):
return f'<a href="/user/{self.id}">{escape(self.name)}</a>'
>>> user = User(3, "<script>")
>>> escape(user)
Markup('<a href="/users/3"><script></a>')
Create and Upload Python Package to PyPI
- Packaging Python Projects — Python Packaging User Guide
- Python: Creating a pip installable package – Python for HPC: Community Materials (betterscientificsoftware.github.io) – pyexample
- How to Create and Upload Your First Python Package to PyPI (freecodecamp.org)
ติดตั้ง Package
build – ใช้ build
twine – ใช้อัพโหลด
python -m pip install --upgrade pip python -m pip install --upgrade build python -m pip install --upgrade twine
สร้างโปรเจ็กส์ตัวอย่าง
packaging_tutorial/ ├── LICENSE ├── pyproject.toml ├── README.md ├── src/ │ └── example_package_phaisarn/ │ ├── __init__.py │ └── example.py └── tests/
ไฟล์ __init__.py เป็นไฟล์เปล่า
ไฟล์ example.py
def add_one(number):
return number + 1
ไดเร็กทอรี่ tests/ เป็นไดเร็กทอรี่ว่างๆ
ไฟล์ pyproject.toml
[build-system]
requires = ["setuptools>=61.0"]
build-backend = "setuptools.build_meta"
[project]
name = "example_package_phaisarn"
version = "0.0.1"
authors = [
{ name="Phaisarn", email="phaisarn@example.com" },
]
description = "A small example package"
readme = "README.md"
requires-python = ">=3.7"
classifiers = [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
]
[project.urls]
"Homepage" = "https://github.com/pypa/phaisarn"
"Bug Tracker" = "https://github.com/pypa/phaisarn/issues"
ไฟล์ README.md
# Example Package This is a simple example package. You can use [Github-flavored Markdown](https://guides.github.com/features/mastering-markdown/) to write your content.
ไฟล์ LICENSE
Copyright (c) 2018 The Python Packaging Authority Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software. THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Generating distribution archives
Now run this command from the same directory where pyproject.toml is located:
python -m build
This command should output a lot of text and once completed should generate two files in the dist directory:
dist/ ├── example_package_phaisarn-0.0.1-py3-none-any.whl └── example_package_phaisarn-0.0.1.tar.gz
Uploading the distribution archives
สร้าง Account ของ TestPyPI ก่อนที่ https://test.pypi.org/account/register/
อัพโหลดด้วย twine
python -m twine upload --repository testpypi dist/*
เข้าดูได้ที่ https://test.pypi.org/project/example-package-phaisarn
Installing your newly uploaded package
สร้าง virtual environment และทำการ activate
> python -m venv venv > .\venv\Scripts\activate
ติดตั้ง package จาก TestPyPI แบบไม่มี dependencies ด้วย --no-deps
python -m pip install -i https://test.pypi.org/simple/ --no-deps example-package-phaisarn
ทดสอบใช้งาน
>>> from example_package_phaisarn import example >>> example.add_one(2) 3
Upgrade package
อัพเกรดจากเวอร์ชัน 0.0.1 เป็นเวอร์ชัน 0.0.2 โดยแก้ไขไฟล์ pyproject.toml
[build-system]
requires = ["setuptools>=61.0"]
build-backend = "setuptools.build_meta"
[project]
name = "example_package_phaisarn"
version = "0.0.2"
authors = [
{ name="Phaisarn", email="phaisarn@example.com" },
]
description = "A small example package"
readme = "README.md"
requires-python = ">=3.7"
classifiers = [
"Programming Language :: Python :: 3",
"License :: OSI Approved :: MIT License",
"Operating System :: OS Independent",
]
[project.urls]
"Homepage" = "https://github.com/pypa/phaisarn"
"Bug Tracker" = "https://github.com/pypa/phaisarn/issues"
สั่ง build
python -m build
จะได้ไฟล์
dist/ ├── example_package_phaisarn-0.0.1-py3-none-any.whl ├── example_package_phaisarn-0.0.1.tar.gz ├── example_package_phaisarn-0.0.2-py3-none-any.whl └── example_package_phaisarn-0.0.2.tar.gz
ให้ลบไฟล์เวอร์ชัน 0.0.1 ออกไป ไม่งั้น twine จะอัพโหลดเวอร์ชัน 0.0.1 แล้วจะ error แบบนี้
Uploading example_package_phaisarn-0.0.1-py3-none-any.whl
100% ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 6.2/6.2 kB • 00:00 • ?
WARNING Error during upload. Retry with the --verbose option for more details.
ERROR HTTPError: 400 Bad Request from https://test.pypi.org/legacy/
File already exists. See https://test.pypi.org/help/#file-name-reuse for more
information.
จะเหลือไฟล์เท่านี้
dist/ ├── example_package_phaisarn-0.0.2-py3-none-any.whl └── example_package_phaisarn-0.0.2.tar.gz
อัพโหลดด้วย twine
python -m twine upload --repository testpypi dist/*
ทดสอบใช้งานเวอร์ชันล่าสุด
สั่งอัพเกรด example_package_phaisarn
python -m pip install -i https://test.pypi.org/simple/ --upgrade example_package_phaisarn
ติดตั้ง Flask
Flask ใช้ Jinja เป็น HTML templates
Install Flask
สร้าง folder สำหรับโปรเจ็กส์
> mkdir myproject ; cd myproject
สร้างไฟล์ requirements.txt
Flask==2.0.2
พิมพ์คำสั่งตามนี้
python -m venv venv .\venv\scripts\activate pip install -r requirements.txt
สร้างไฟล์ app.py หรือชื่ออื่นก็ได้ เช่น hello.py แต่ห้ามชื่อ flask.py
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello_world():
return "<p>Hello, World!</p>"
ไฟล์ชื่อ app.py สั่งรัน Flask แบบนี้
flask run
แต่ถ้าไฟล์ชื่ออื่น เช่น ไฟล์ชื่อ hello.py สั่งรันแบบนี้
flask --app hello run
รันแบบ debug – restarts the server whenever you make changes to the code.
flask run --debug
เปิด browser ไปที่ http://127.0.0.1:5000/
HTML Escaping
from flask import Flask
from markupsafe import escape
app = Flask(__name__)
@app.route("/")
def hello_world():
return "<p>Hello, World!</p>"
@app.route("/<name>")
def hello(name):
return f"Hello, {escape(name)}!"
ไปที่ http://127.0.0.1:5000/jack
จะได้ Hello, jack!
Routing
from flask import Flask
from markupsafe import escape
app = Flask(__name__)
@app.route('/')
def index():
return 'Index Page'
@app.route('/hello')
def hello_world():
return 'Hello, World'
@app.route("/<name>")
def hello(name):
return f"Hello, {escape(name)}!"
Variable Rules
from flask import Flask
from markupsafe import escape
app = Flask(__name__)
@app.route('/')
def index():
return 'Index Page'
@app.route('/hello')
def hello_world():
return 'Hello, World'
@app.route("/<name>")
def hello(name):
return f"Hello, {escape(name)}!"
@app.route('/user/<username>')
def show_user_profile(username):
# show the user profile for that user
return f'User {escape(username)}'
@app.route('/post/<int:post_id>')
def show_post(post_id):
# show the post with the given id, the id is an integer
return f'Post {post_id}'
@app.route('/path/<path:subpath>')
def show_subpath(subpath):
# show the subpath after /path/
return f'Subpath {escape(subpath)}'
Converter types:
string | (default) accepts any text without a slash |
int | accepts positive integers |
float | accepts positive floating point values |
path | like string but also accepts slashes |
uuid | accepts UUID strings |
Python Naming Conventions
The naming styles
b(single lowercase letter)B(single uppercase letter)lowercaselower_case_with_underscoresUPPERCASEUPPER_CASE_WITH_UNDERSCORESCapitalizedWords(or CapWords, or CamelCase – so named because of the bumpy look of its letters [4]). This is also sometimes known as StudlyCaps.Note: When using acronyms in CapWords, capitalize all the letters of the acronym. Thus HTTPServerError is better than HttpServerError.mixedCase(differs from CapitalizedWords by initial lowercase character!)Capitalized_Words_With_Underscores(ugly!)
Class Names
Class names should normally use the CapWords convention.
Function Names
Function names should be lowercase, with words separated by underscores as necessary to improve readability. (lower_case_with_underscores)
Variable Names
Variable names follow the same convention as function names.