
- ตรวจสอบไฟล์ข้อมูล
- Read in the Parquet Files
- Read in the Parquet Files – Schema
1. ตรวจสอบไฟล์ข้อมูล
ตัวอย่างไฟล์ parquet นำมาจาก kylo/samples/sample-data/parquet at master · Teradata/kylo · GitHub และทำการลบไฟล์ README.txt ออกก่อน ค่อยนำมาทดสอบ
%fs ls /mnt/training/sample_parquet/
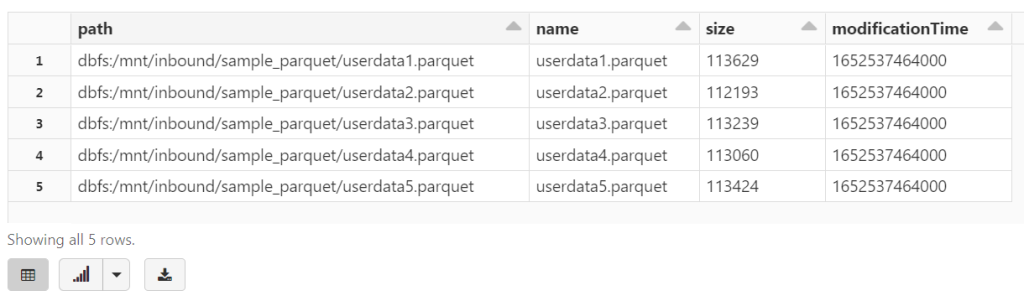
2. Read in the Parquet Files
To read in this files, we will specify the location of the parquet directory.
parquetFile = "/mnt/training/sample_parquet/"
tempDF = (spark.read
.parquet(parquetFile)
)
tempDF.printSchema()
root |-- registration_dttm: timestamp (nullable = true) |-- id: integer (nullable = true) |-- first_name: string (nullable = true) |-- last_name: string (nullable = true) |-- email: string (nullable = true) |-- gender: string (nullable = true) |-- ip_address: string (nullable = true) |-- cc: string (nullable = true) |-- country: string (nullable = true) |-- birthdate: string (nullable = true) |-- salary: double (nullable = true) |-- title: string (nullable = true) |-- comments: string (nullable = true)
display(tempDF)
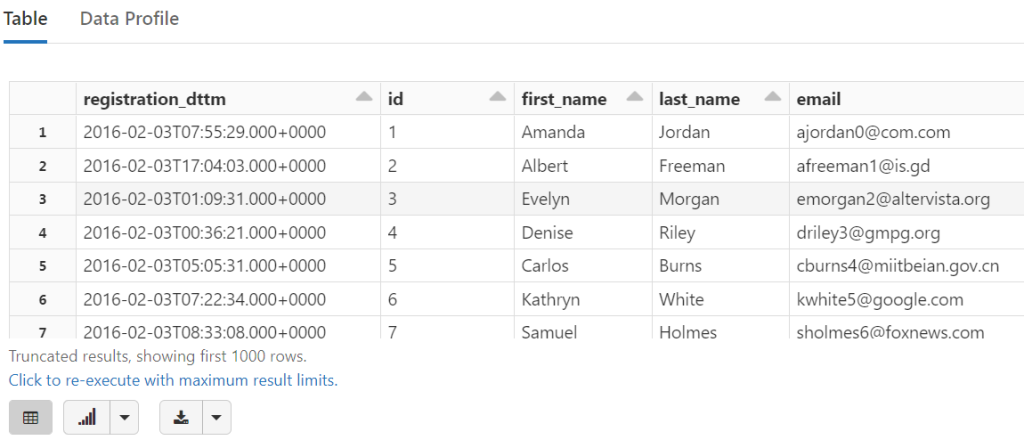
Review: Reading from Parquet Files
- We do not need to specify the schema – the column names and data types are stored in the parquet files.
- Only one job is required to read that schema from the parquet file’s metadata.
- The parquet reader can “read” the schema very quickly because it’s reading that schema from the metadata.
3. Read in the Parquet Files – Schema
If you want to avoid the extra job entirely, we can, again, specify the schema even for parquet files:
** WARNING ** Providing a schema may avoid this one-time hit to determine the DataFrame's schema. However, if you specify the wrong schema it will conflict with the true schema and will result in an analysis exception at runtime.
# Required for StructField, StringType, IntegerType, etc.
from pyspark.sql.types import *
parquetSchema = StructType(
[
StructField("registration_dttm", TimestampType(), False),
StructField("id", IntegerType(), False),
StructField("first_name", StringType(), False),
StructField("last_name", StringType(), False),
StructField("email", StringType(), False),
StructField("gender", StringType(), False),
StructField("ip_address", StringType(), False),
StructField("cc", StringType(), False),
StructField("country", StringType(), False),
StructField("birthdate", StringType(), False),
StructField("salary", DoubleType(), False),
StructField("title", StringType(), False),
StructField("comments", StringType(), False)
]
)
- TimestampType (Spark 3.2.1 JavaDoc) (apache.org)
- IntegerType (Spark 3.2.1 JavaDoc) (apache.org)
- DoubleType (Spark 3.2.1 JavaDoc) (apache.org)
(spark.read # The DataFrameReader .schema(parquetSchema) # Use the specified schema .parquet(parquetFile) # Creates a DataFrame from Parquet after reading in the file .printSchema() # Print the DataFrame's schema )
root |-- registration_dttm: timestamp (nullable = true) |-- id: integer (nullable = true) |-- first_name: string (nullable = true) |-- last_name: string (nullable = true) |-- email: string (nullable = true) |-- gender: string (nullable = true) |-- ip_address: string (nullable = true) |-- cc: string (nullable = true) |-- country: string (nullable = true) |-- birthdate: string (nullable = true) |-- salary: double (nullable = true) |-- title: string (nullable = true) |-- comments: string (nullable = true)
In most/many cases, people do not provide the schema for Parquet files because reading in the schema is such a cheap process.